お待たせしました。今回からはPowerQueryでの整理クエリの説明に入っていきます。

今回のテーマはPDF注文書データを一例に、PowerQueyを用いた複雑な構造データの集計技術やその後の応用事例を学ぶことを目的としています。↓
- 電子PDFをPowerQueryで集計・成形する流れを知ること
- 少し複雑な構造のデータをPowerQueryで成形する際の考え方やテクニックを学ぶこと
- PowerQueryで集計したデータをexcelで取り扱う事例を学ぶこと
本記事(#3)では#2でグループわけした未整理状態のデータを整理するクエリについてそれぞれ説明します。
- PowerQueyで複雑な構造のデータを整理するクエリの詳細
- 行列の入れ替えステップを上手く利用する
- クエリステップを参照することで、変化のあるデータに対応する(中級者向け)
少し長いですが、各グループの整理ステップについて画像付きで詳しく解説しています。
全体フローのおさらい・今回の流れ
今回は、ぐちゃぐちゃな形のデータを、列と行がしっかりと揃っているテーブル形式にしていくんだよね?
そもそも、縦や横に散らばっている部分が散見されるけど、そういったデータでも可能なの?
はい!。基本的にはどれだけ複雑なデータでも1つずつ整理すれば可能です。
ただし少し工夫が必要です。実際に想定外の問題も経験したので、そこも踏まえて紹介します。
前回からのおさらいです。PDFの注文書データを整理してデータベース形式にするためにPowerQueryでの操作を以下①~⑩を実施していきます。以下の図が最終的な成形のイメージ図でした。
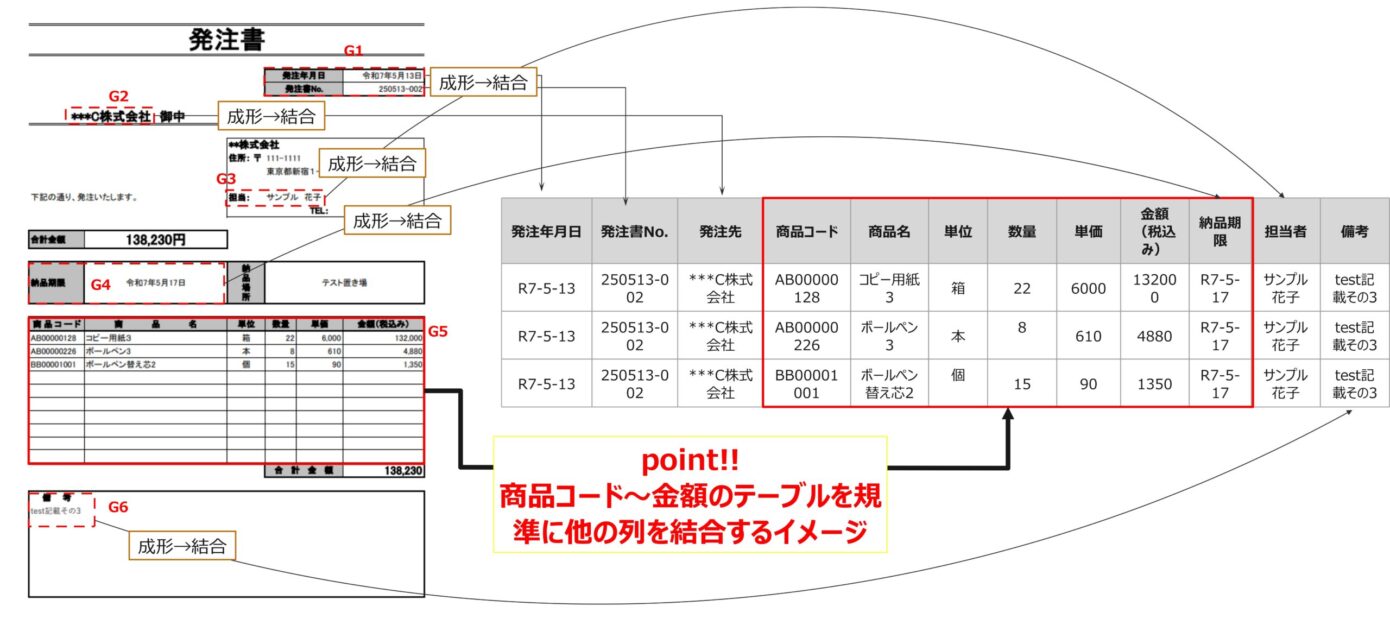
今回はグループ別の整理クエリに当たる部分(↓④)について説明します。また④を行う上で前準備として③図解フローを作成しましたので合わせて添付します。
PowerQueyでのグループ別整理の流れ
各操作の前に少し準備を行います。前回までに実施したグループ化のクエリを参照して新たに6個のクエリを作成しておきます。これは6グループ別に整理操作のクエリを分けるためです。※一つのクエリで完結することもできるのですが、整理ステップが増えメンテナンス等しずらくなるので今回のような手法をとっています。
また次から、各グループ毎の整理クエリについて詳細まとめていきますが、基本的には
- 行列の入れ替え
- 不要な行の削除
- 行列の入れ替え(不要列が消えて元に戻る)
- 細かい調整
の流れが多くなっています。
ややこしいね。行列の入れ替えをして再度戻しているけど無駄な操作じゃないの?
不要な列はそのまま消せばいいんじゃないの?
気持ちはよくわかります。私も最初は普通に消そうとしたのですが、同じPDFの列方向が全て同じと限らないということが判明して、このような列で消さずに行方向で削除する手法をとっています。
※列を指定して消さないの理由については最後のセクションで簡単に説明します。
グループ1の整理
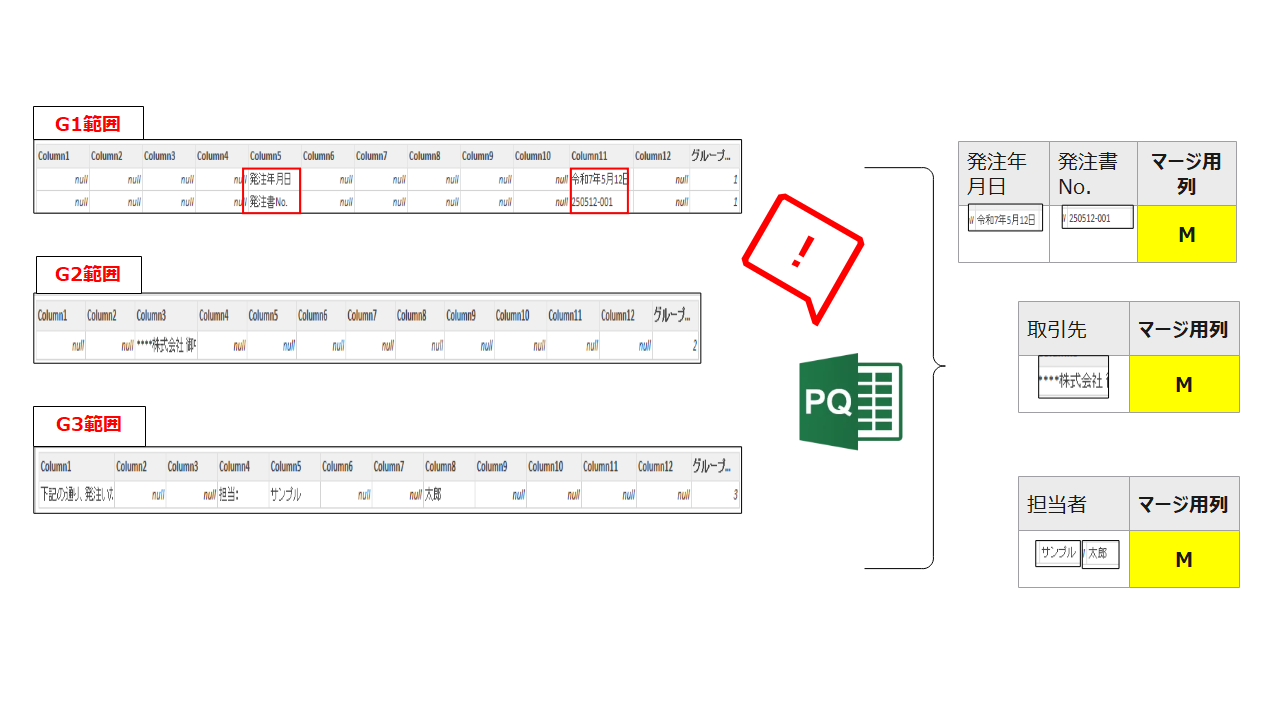
グループ1の範囲の成形ステップ図は以下のような流れで、発注年月日と発注書Noを列項目とする1行テーブルに成形します。
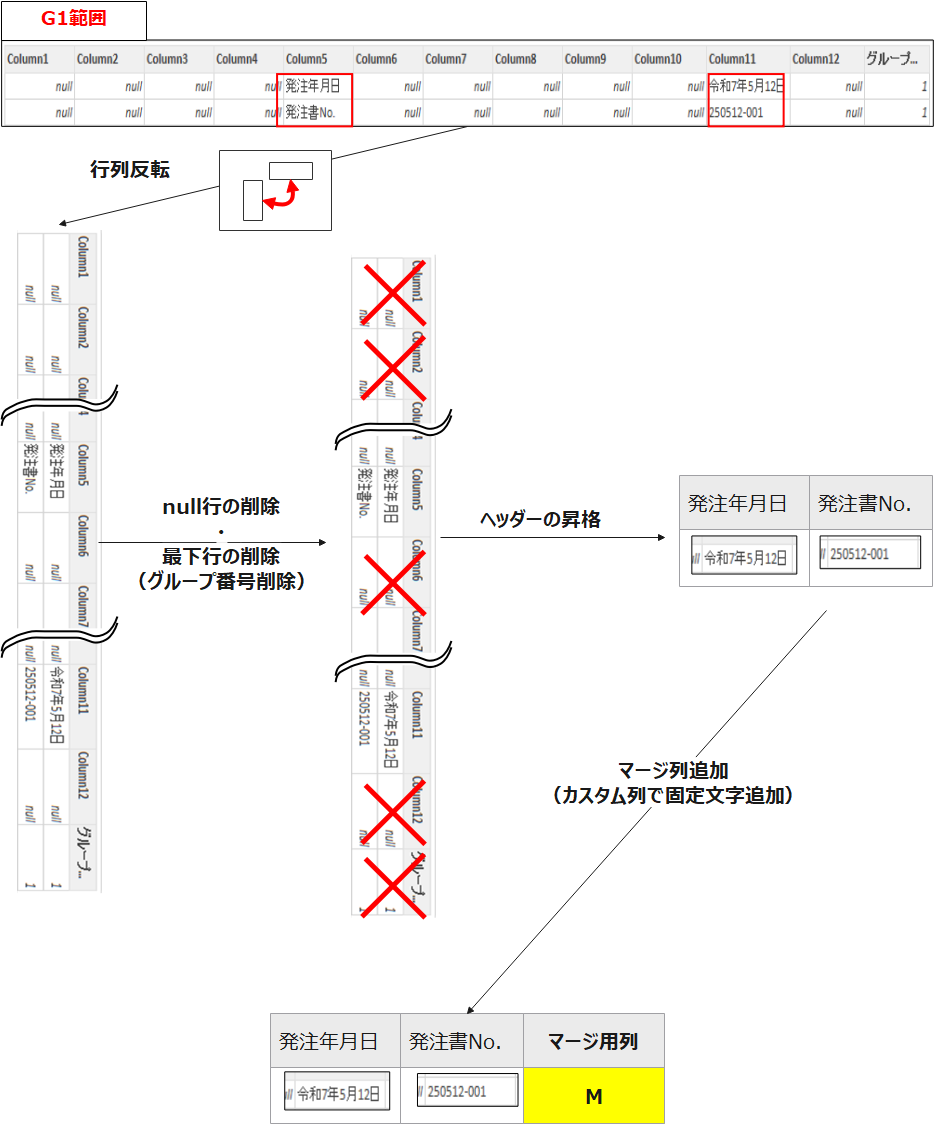
テーブルをクリックする→対象のテーブルが展開されます※グループ2~6も同様です
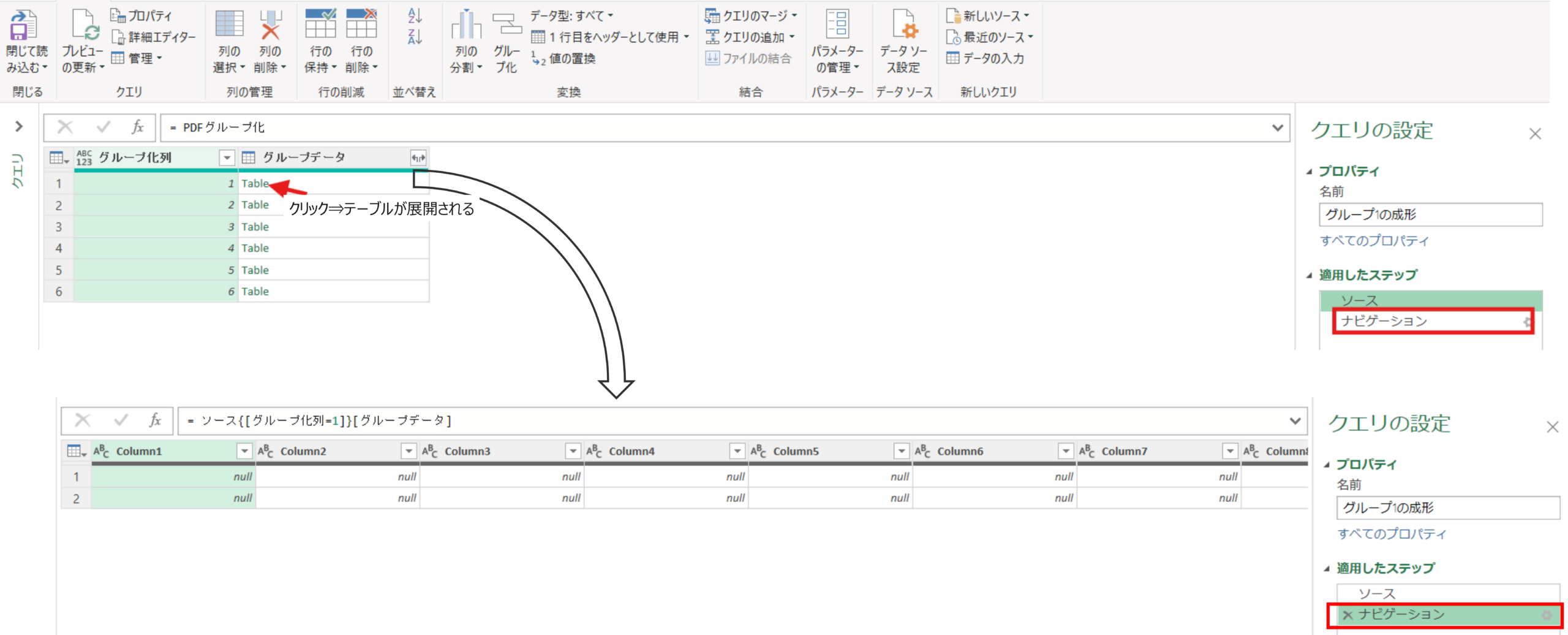
ソース = PDFグループ化,
#"1" = ソース{[グループ化列=1]}[グループデータ]次に変換タブの行列の入れ替えを実施します。この操作をすることで列1に発注年月日、列2に発注書No.をもつテーブル形状に変更されます。
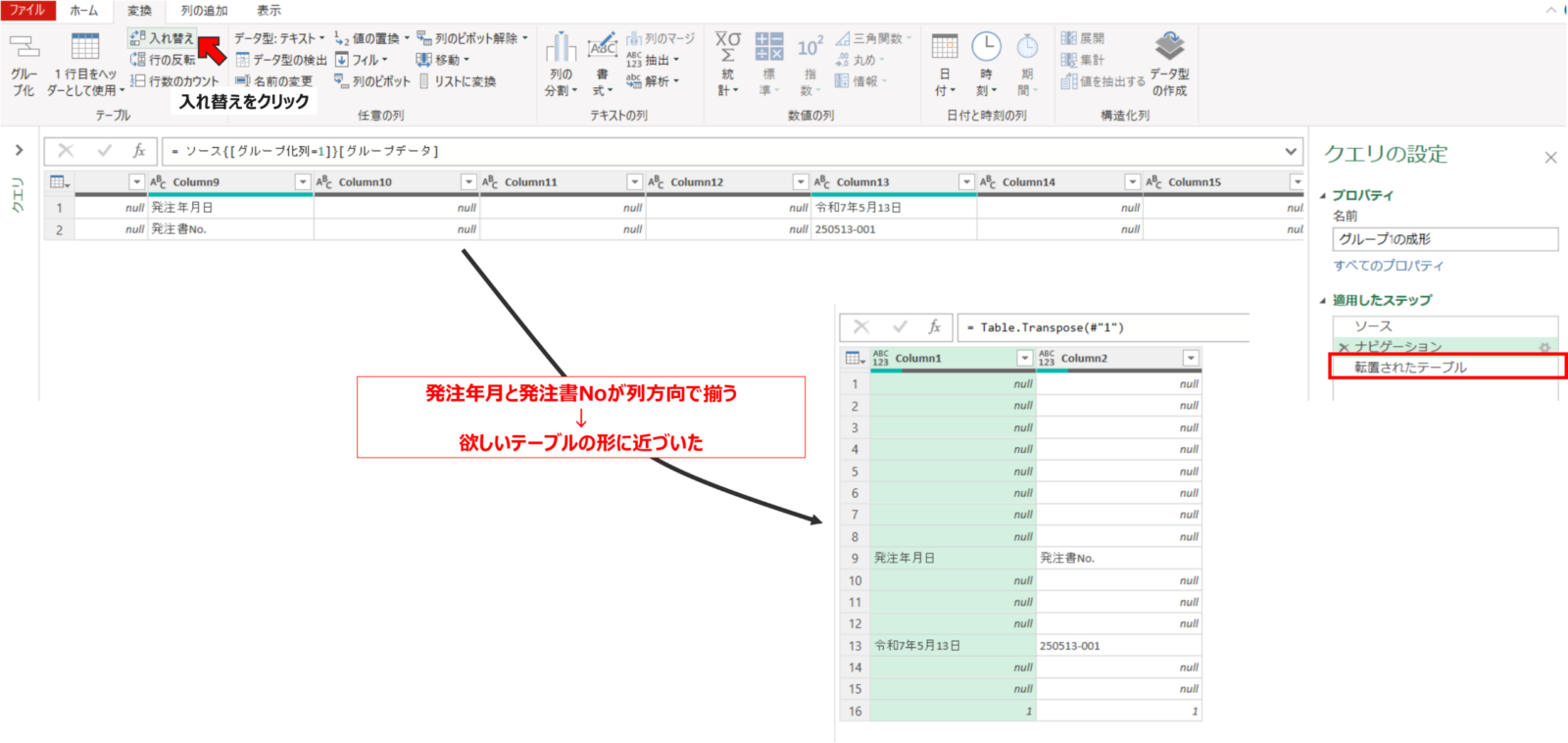
転置されたテーブル = Table.Transpose(#"1")次にホームタブの行の削除の空白行の削除を選択します。これによって列1と列2双方がnullの行が削除されます。
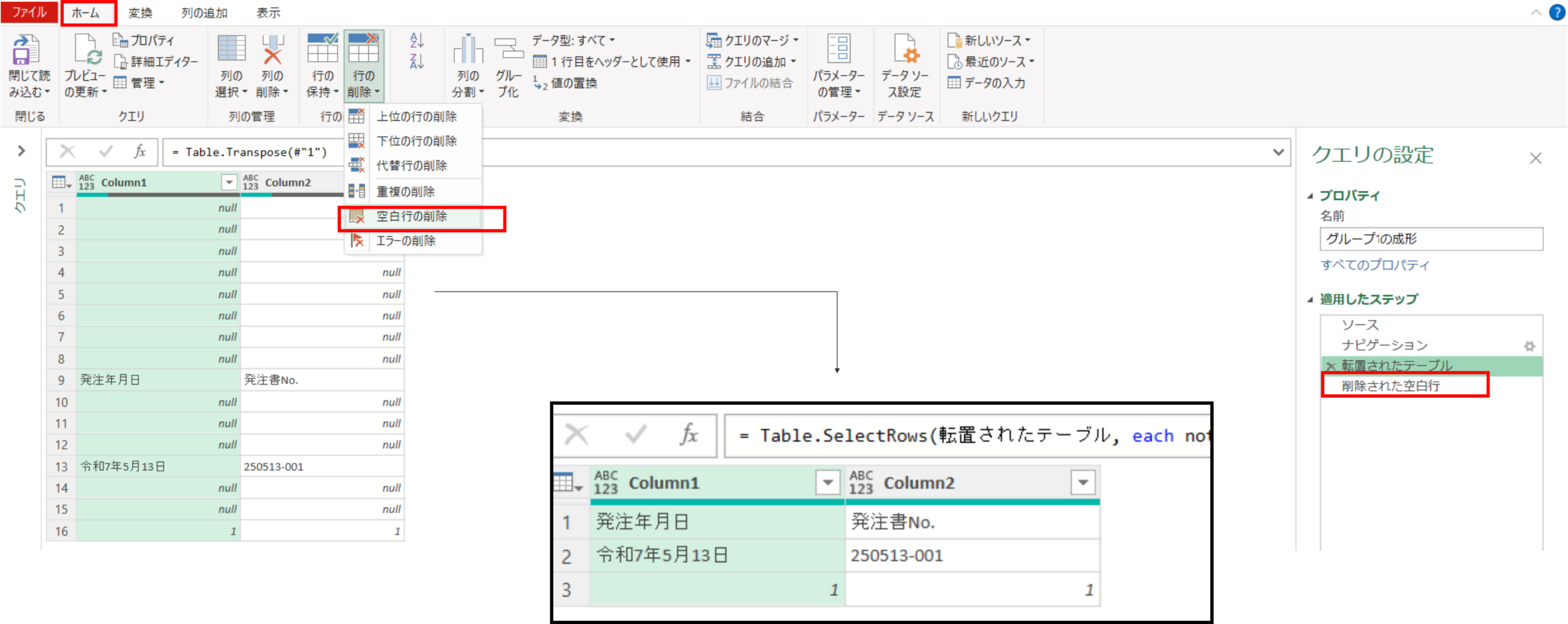
削除された空白行 = Table.SelectRows(転置されたテーブル, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))次にホームタブの行の下位の行の削除より下1行を削除します。(不要なG番号を削除)
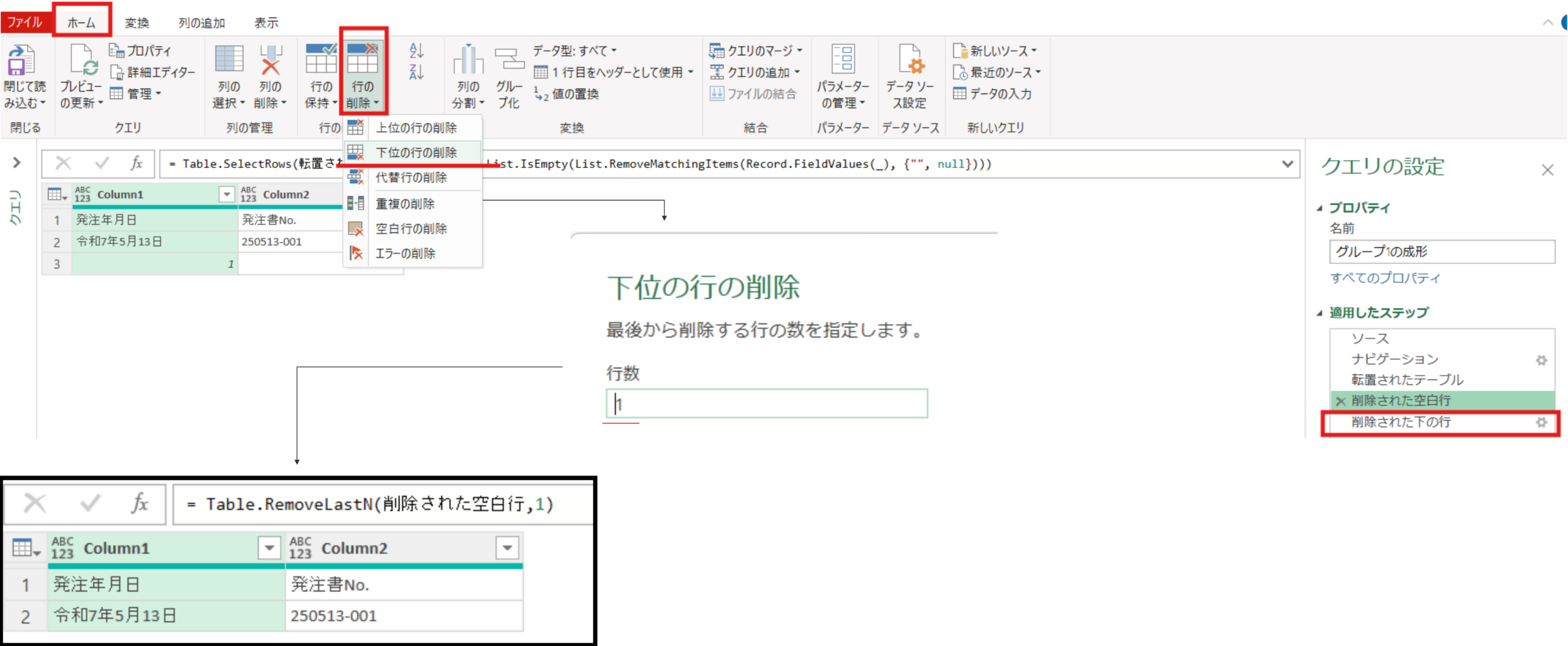
削除された下の行 = Table.RemoveLastN(削除された空白行,1)次にホームタブのヘッダー昇格にて、1行目を列項目にします。
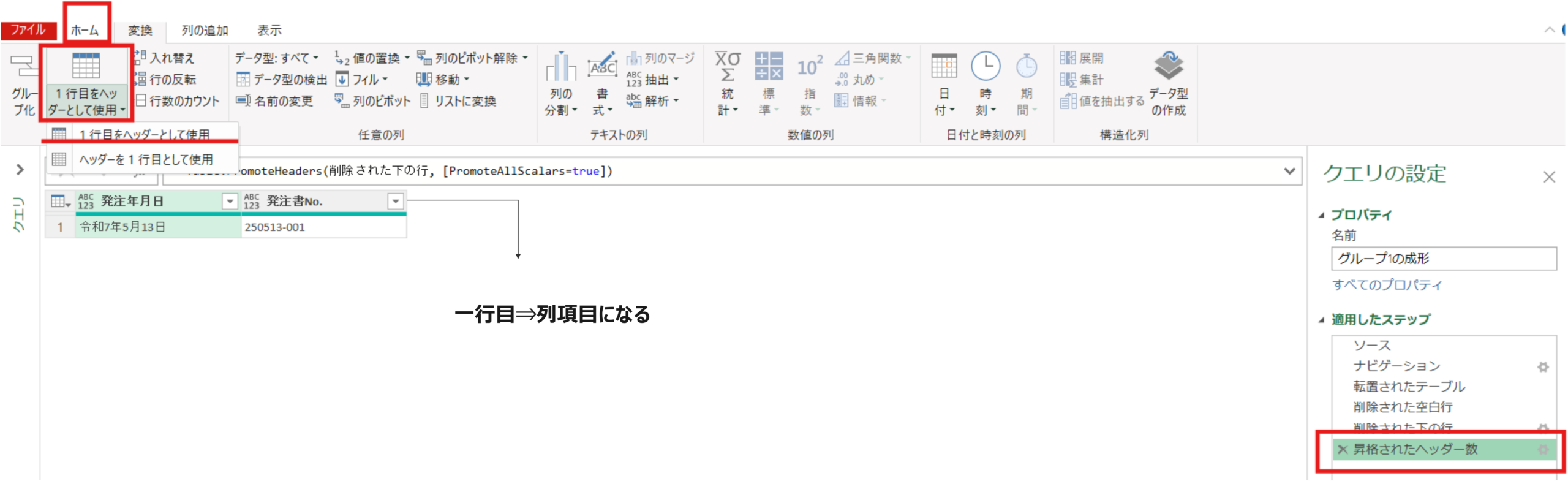
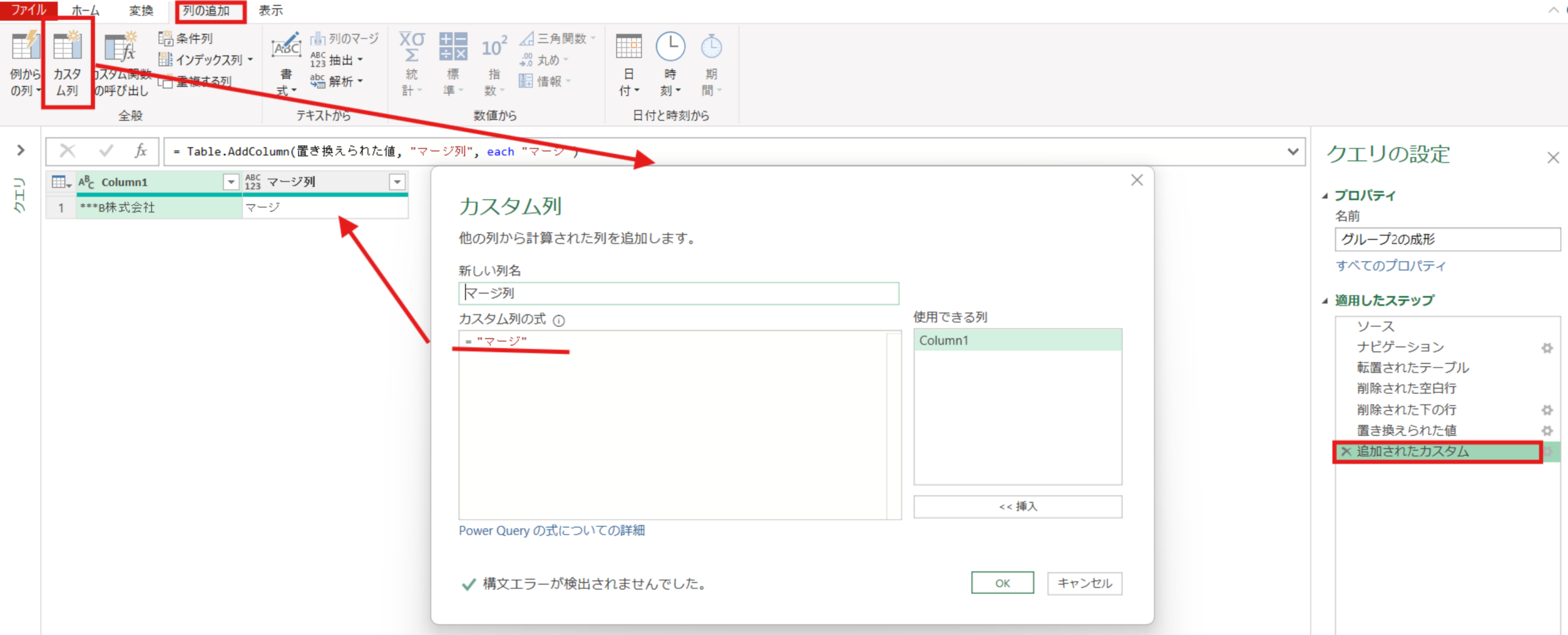
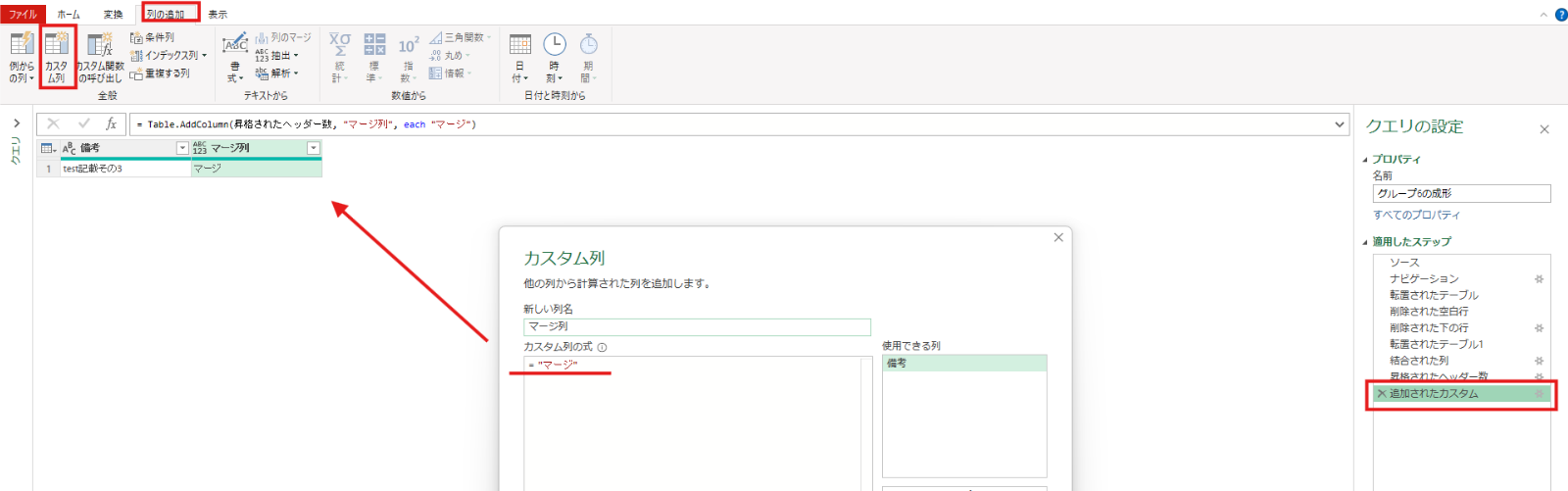
昇格されたヘッダー数 = Table.PromoteHeaders(削除された下の行, [PromoteAllScalars=true])最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。これは最後にグループ1~グループ6を結合するときに左外部結合というテーブルのマージを用いる手法を用いるのですが、その際に必要なテーブルのキーの役割を持ちます。そのためグループ1~6全てで同様に追加しています。
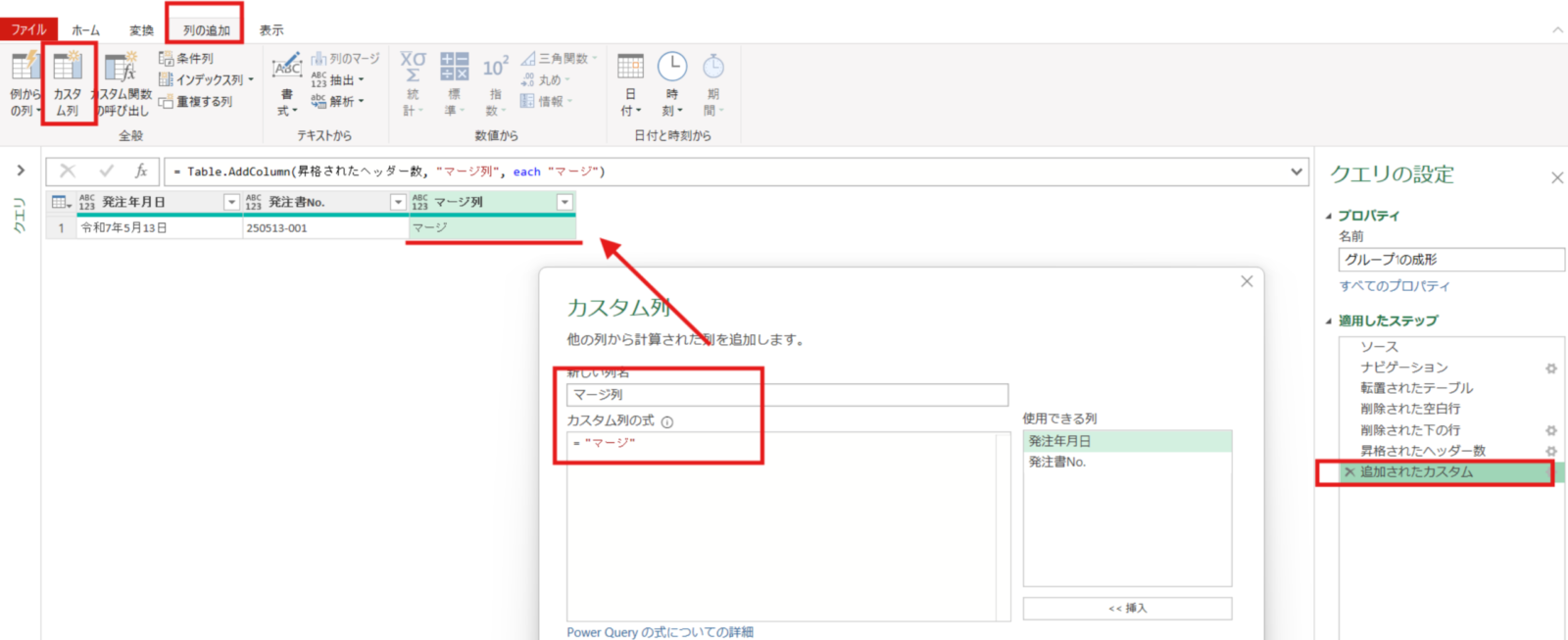
追加されたカスタム = Table.AddColumn(昇格されたヘッダー数, "マージ列", each "マージ")グループ2の整理
グループ2の範囲の成形ステップ図は以下のような流れで、発注先を列にもつ1行テーブルに成形します
テーブル2を展開します(G1~G6で同様)
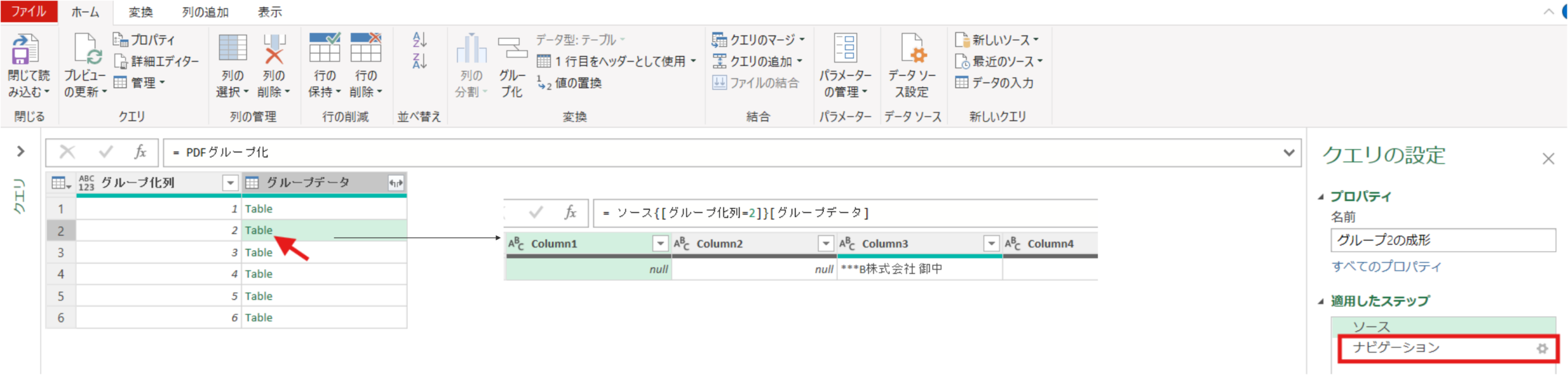
ソース = PDFグループ化,
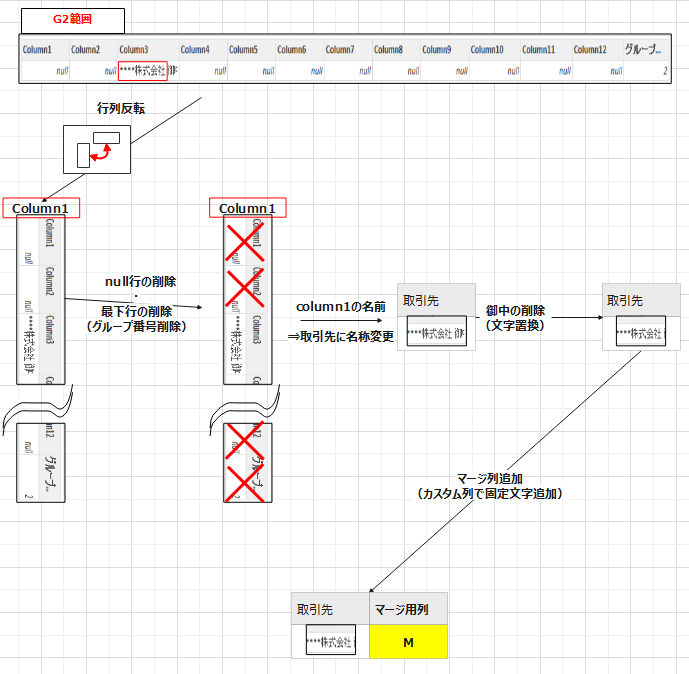
#"2" = ソース{[グループ化列=2]}[グループデータ]行列の入れ替えをします。これにより列1に取引先情報を持つテーブルの形になります。
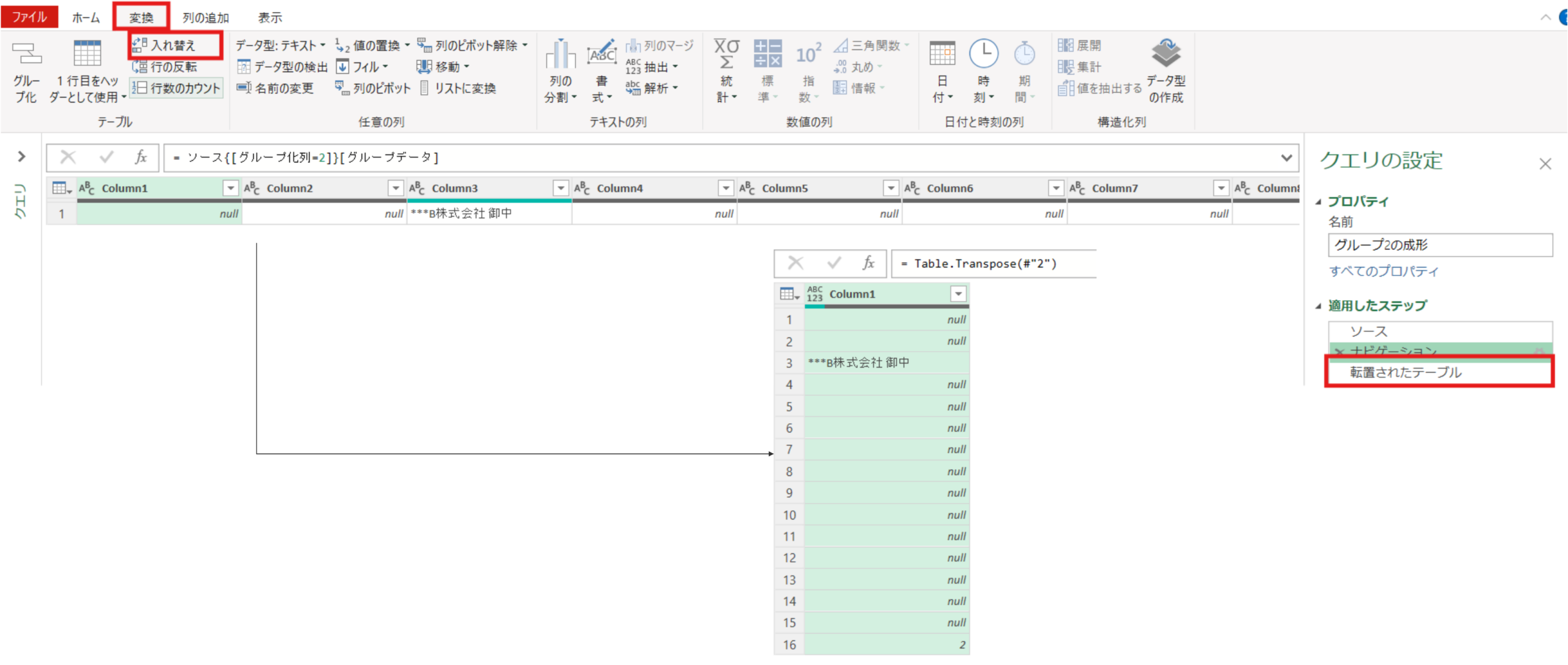
転置されたテーブル = Table.Transpose(#"2")ホームタブの空白行の削除の実施⇒下位の行の削除で下位1行を削除します。これによって列1に取引先+御中(不要文字)を1行もつテーブルに変換されます。
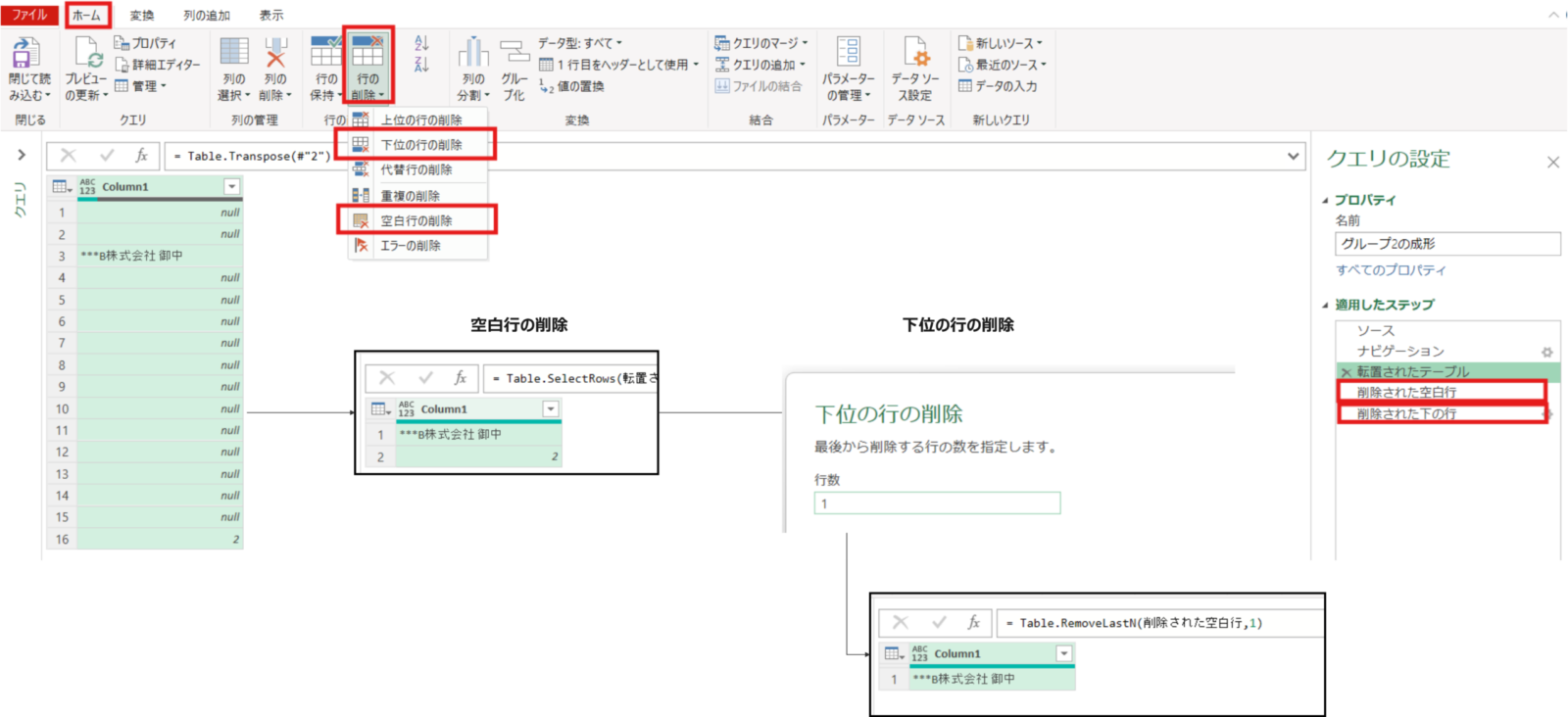
削除された空白行 = Table.SelectRows(転置されたテーブル, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))削除された下の行 = Table.RemoveLastN(削除された空白行,1)列1を選択した状態で変換タブの値の置換を押します。今回不要な株式会社****内の御中を空白に置換します↓
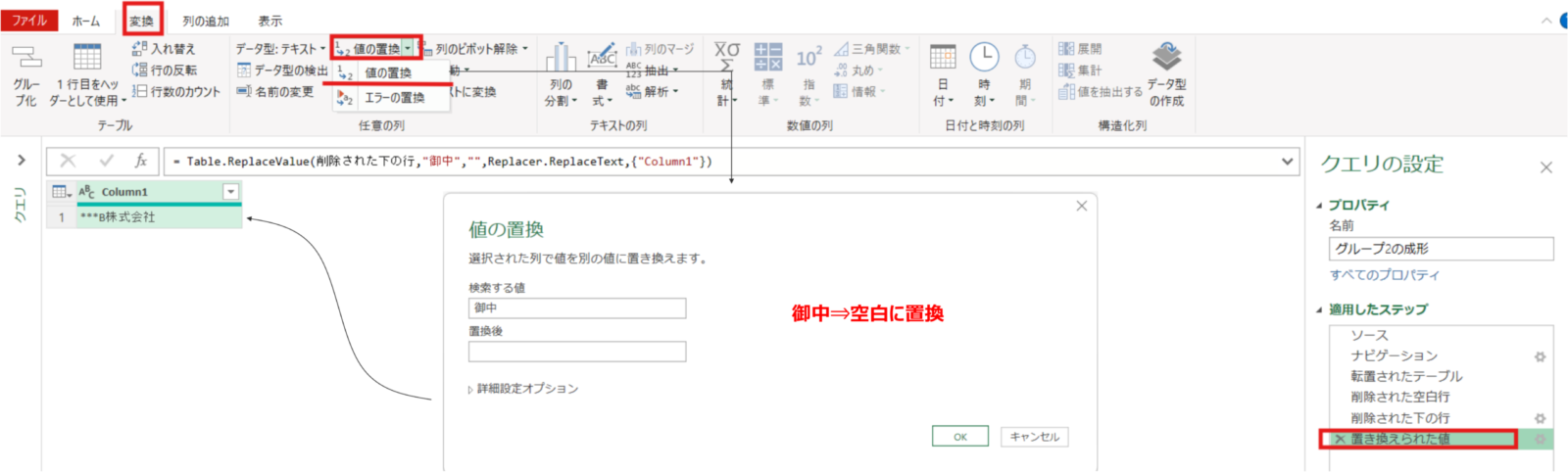
置き換えられた値 = Table.ReplaceValue(削除された下の行,"御中","",Replacer.ReplaceText,{"Column1"})(追記)列1(Column1)の名前を”取引先”に変更します

#"名前が変更された列 " = Table.RenameColumns(置き換えられた値,{{"Column1", "取引先"}})最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。(G1~G6共通)
追加されたカスタム = Table.AddColumn(置き換えられた値, "マージ列", each "マージ")グループ3の整理
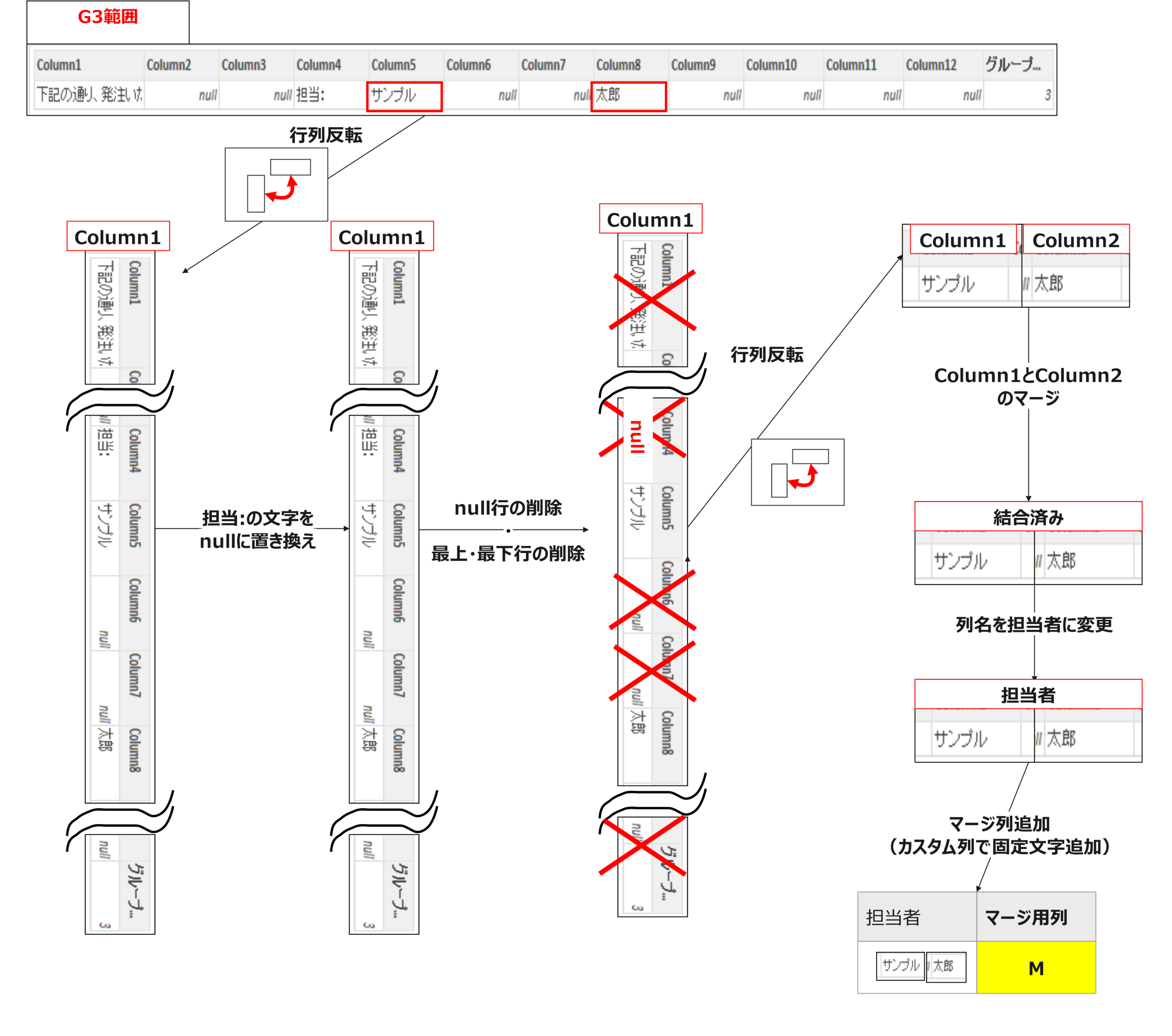
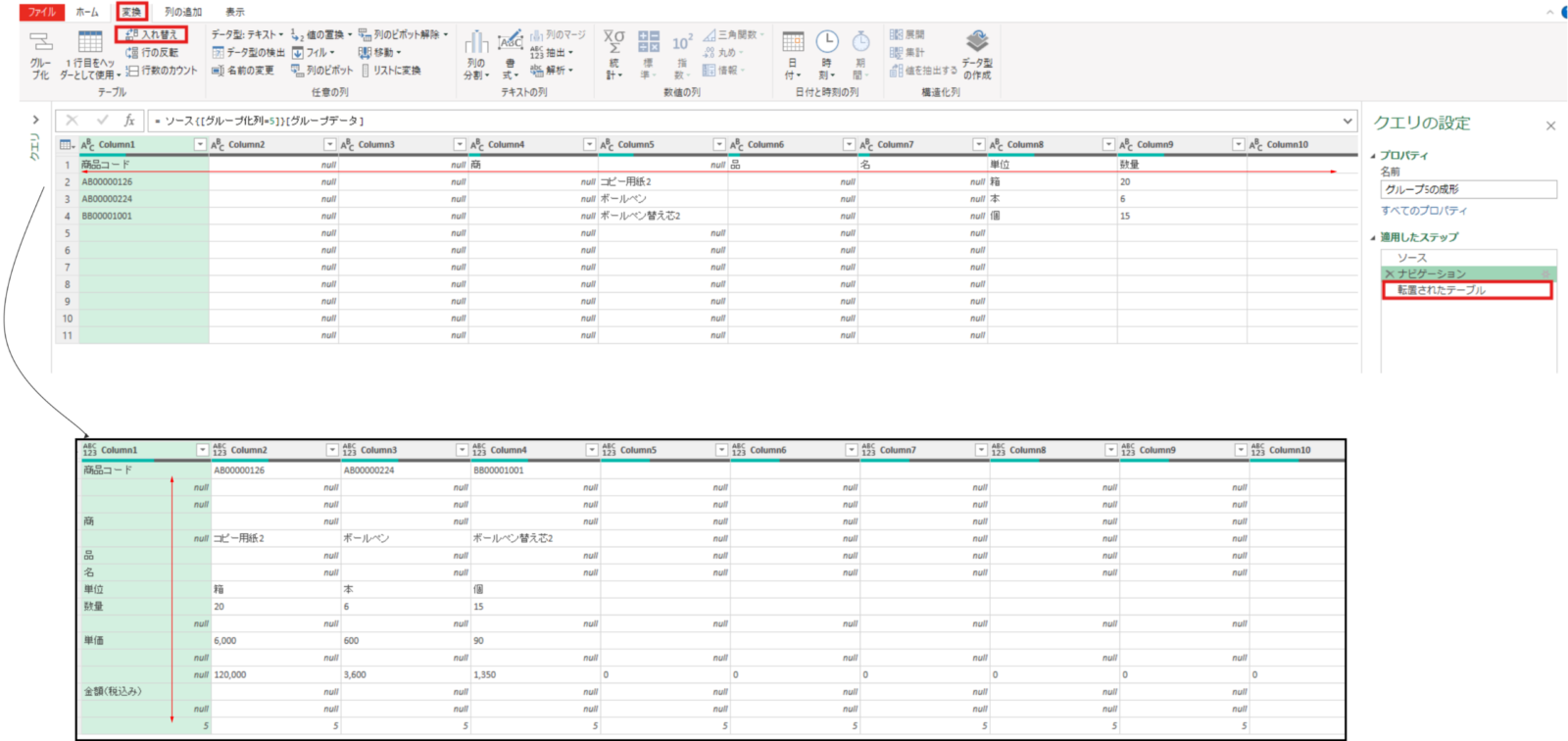
グループ3は以下のような流れで発注担当者を列情報に持つ1行のテーブルに成形します。
グループ3のテーブルを展開します。
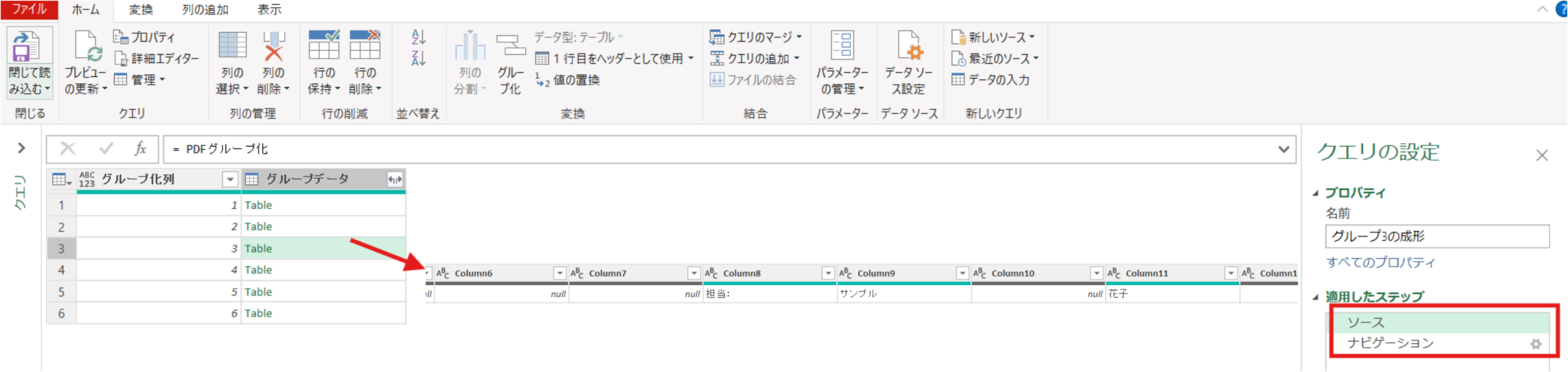
ソース = PDFグループ化,
#"3" = ソース{[グループ化列=3]}[グループデータ]行列の入れ替えを実施します。これは担当者の情報を行方向で整理(不用行を削除)するための前準備のステップとなります。
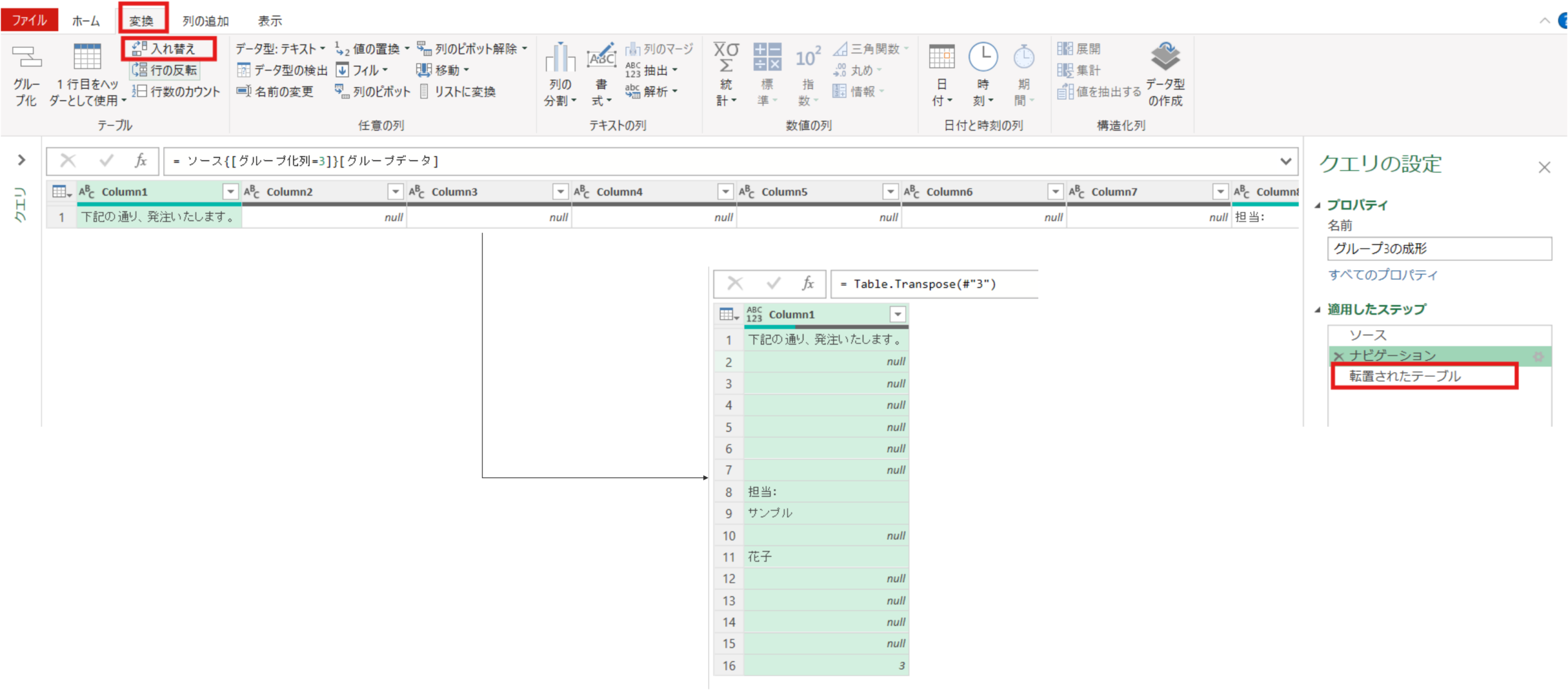
転置されたテーブル = Table.Transpose(#"3")①空白行の削除②下位1行の削除③上位2行の削除を実施します。→この操作で今回必要な担当者名(苗字と名前部分)のみが列1に残りました。
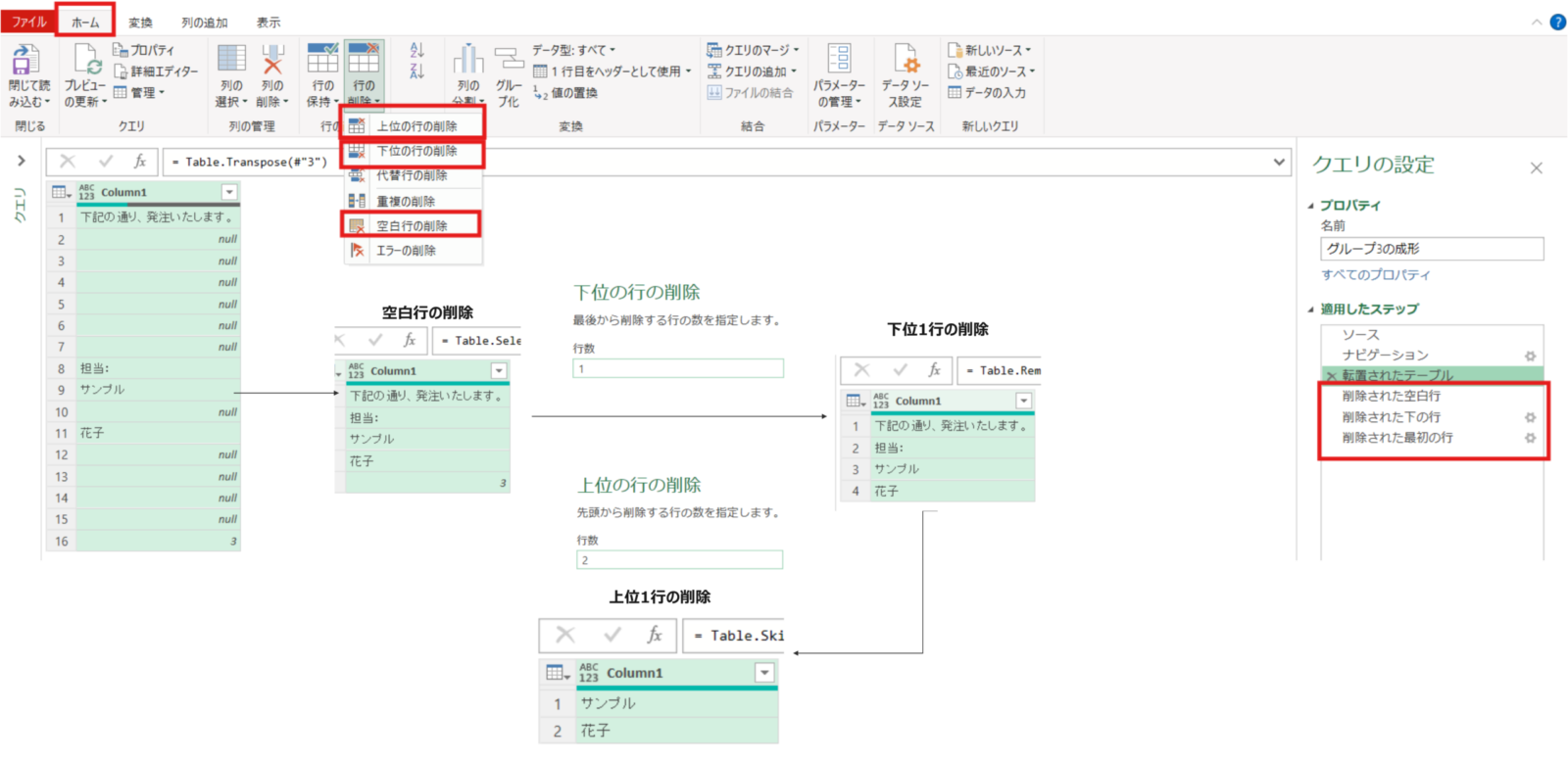
削除された空白行 = Table.SelectRows(転置されたテーブル, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))削除された下の行 = Table.RemoveLastN(削除された空白行,1)削除された最初の行 = Table.Skip(削除された下の行,2)次に、再度行列の入れ替えを実施⇒苗字(サンプル)が列1、名前(花子)が列2となりますがこの列1と列2をマージして1列の担当者名列にします。
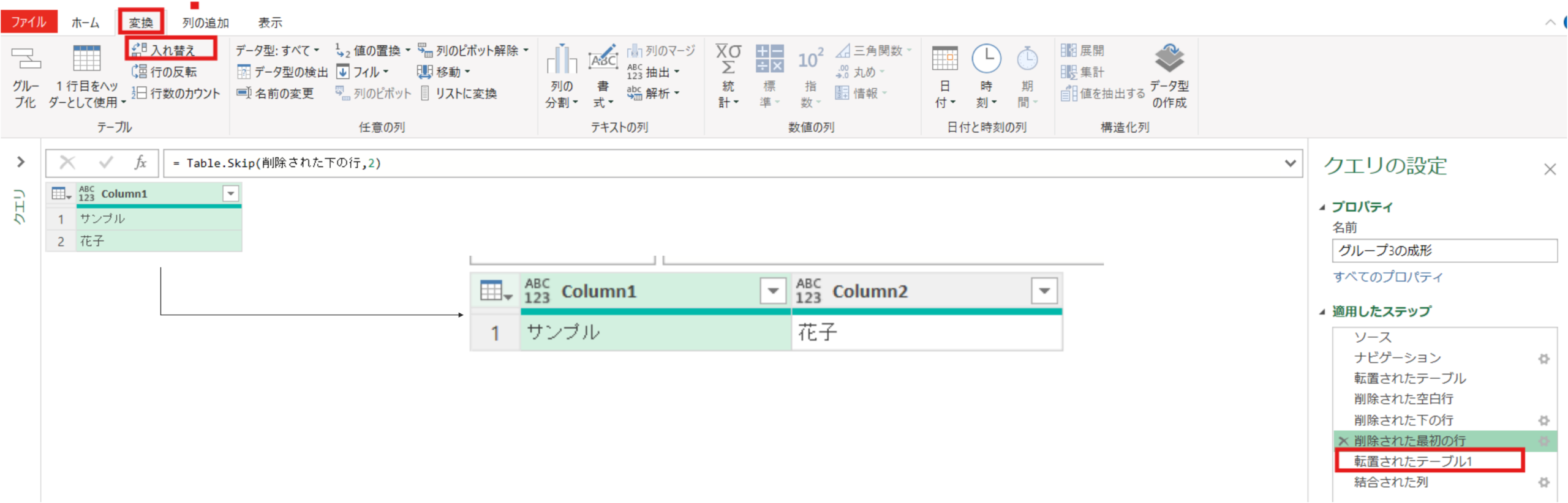
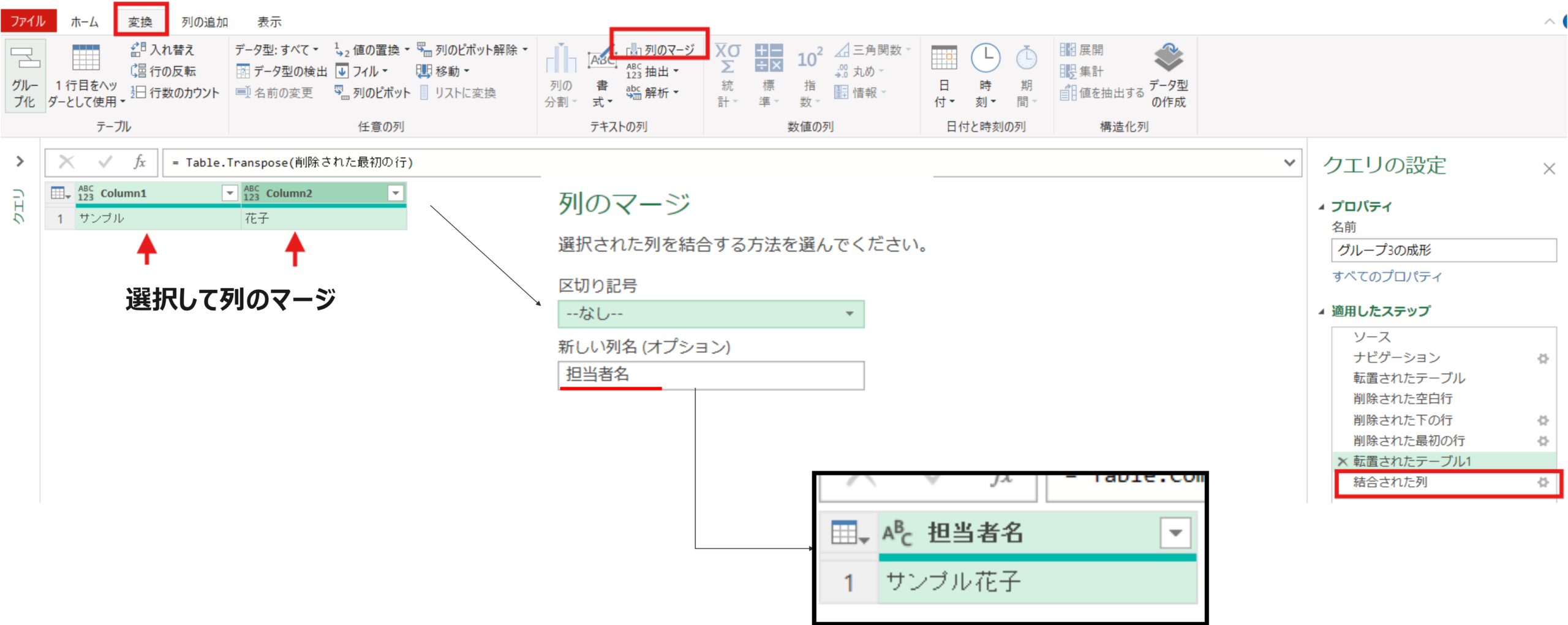
転置されたテーブル1 = Table.Transpose(削除された最初の行)結合された列 = Table.CombineColumns(転置されたテーブル1,{"Column1", "Column2"},Combiner.CombineTextByDelimiter("", QuoteStyle.None),"担当者名")最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。(G1~G6共通)
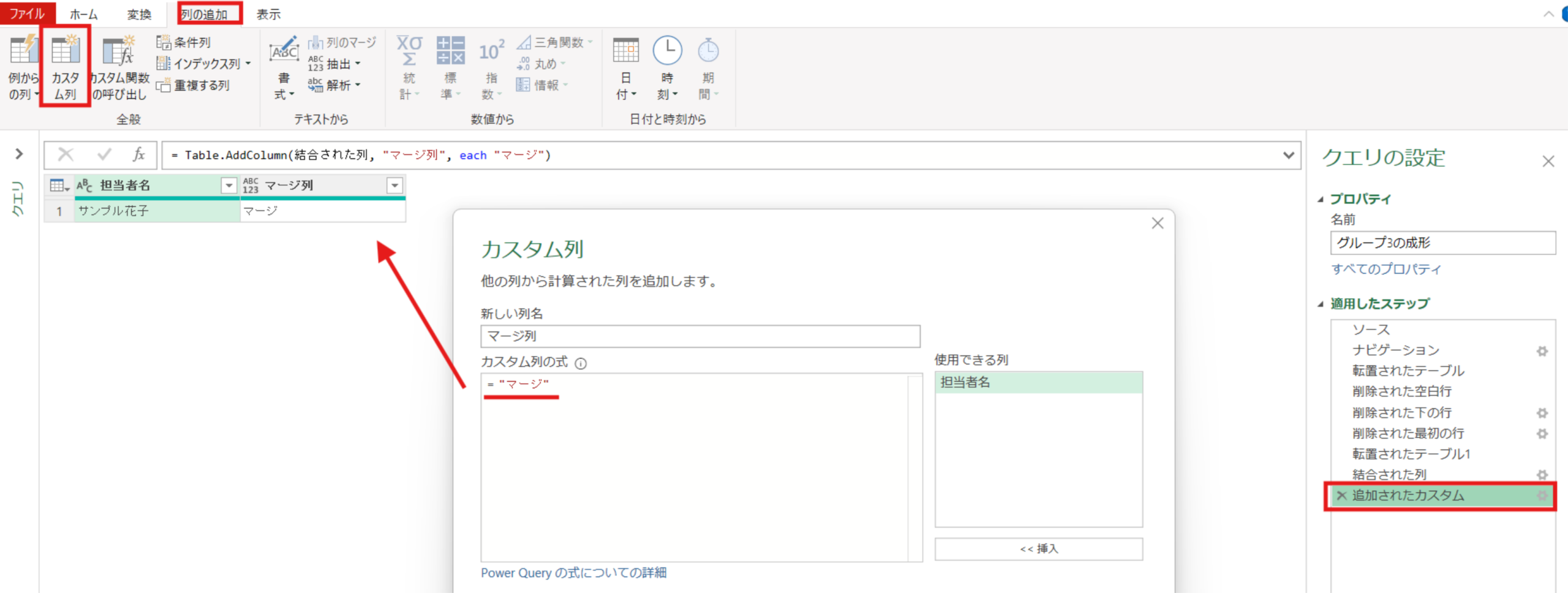
追加されたカスタム = Table.AddColumn(結合された列, "マージ列", each "マージ")グループ4の整理
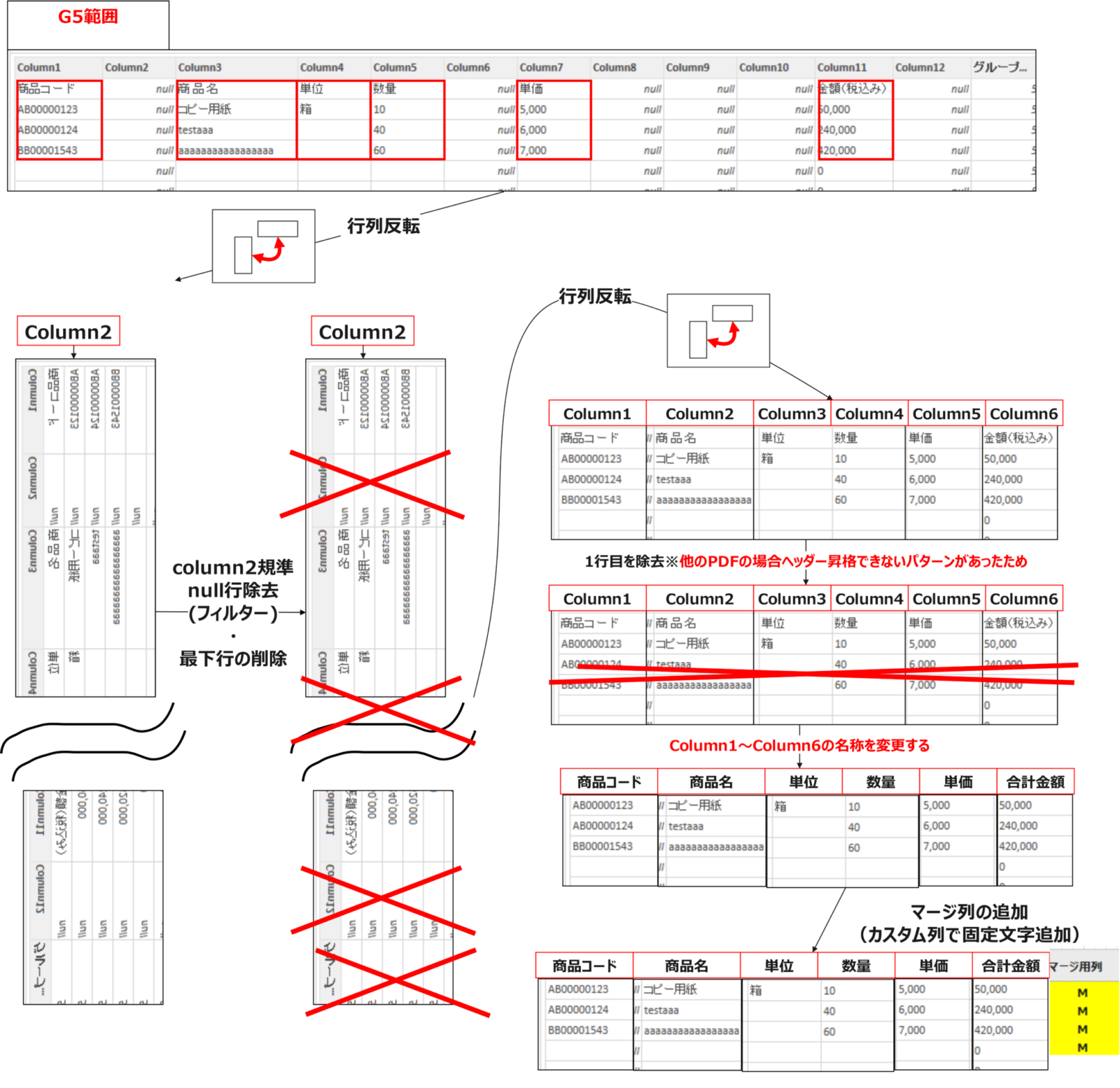
以下のような流れで、納品期限を列に持つ1行テーブルへと整理しています。グループ4は少し遠回りして納品期限の情報を取得しています。→不要な列を特定するために行列の入れ替え後、ある特定文字以降のインデックス番号を取得し以降の番号行をフィルターで削除することで整理しています。※あくまで不要行削除の1例としてこのようなやり方を実装
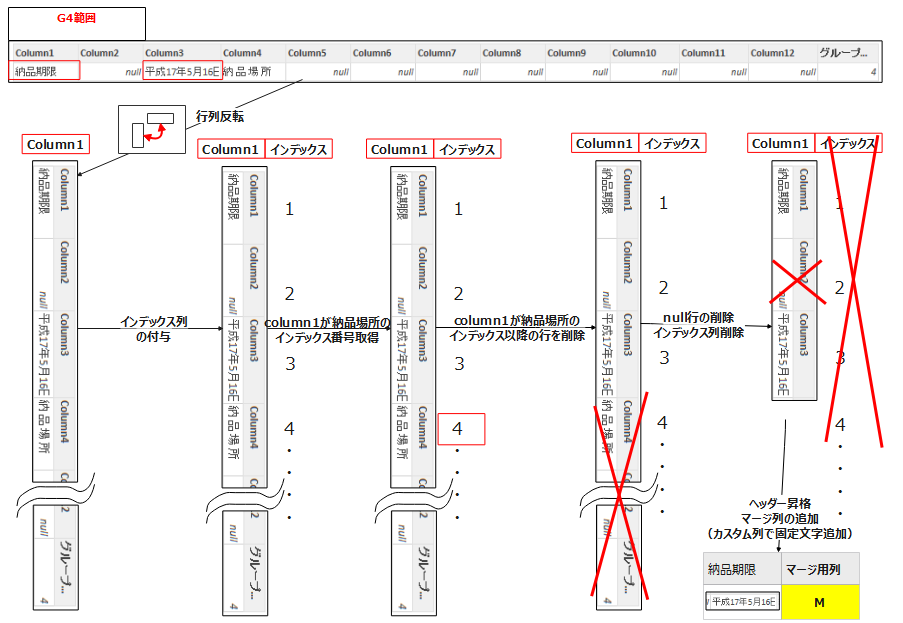
まずはテーブル4をクリックしてテーブルを展開します
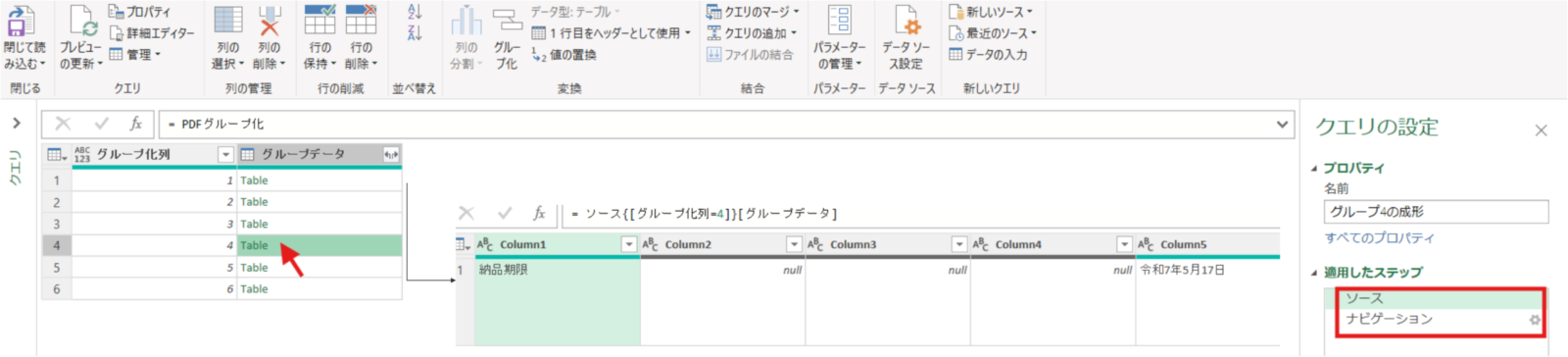
ソース = PDFグループ化,
#"4" = ソース{[グループ化列=4]}[グループデータ]次に変換タブの行列の入れ替えを実施します。この操作をすることで列1に納品期限の情報を持つ形に変換されます。
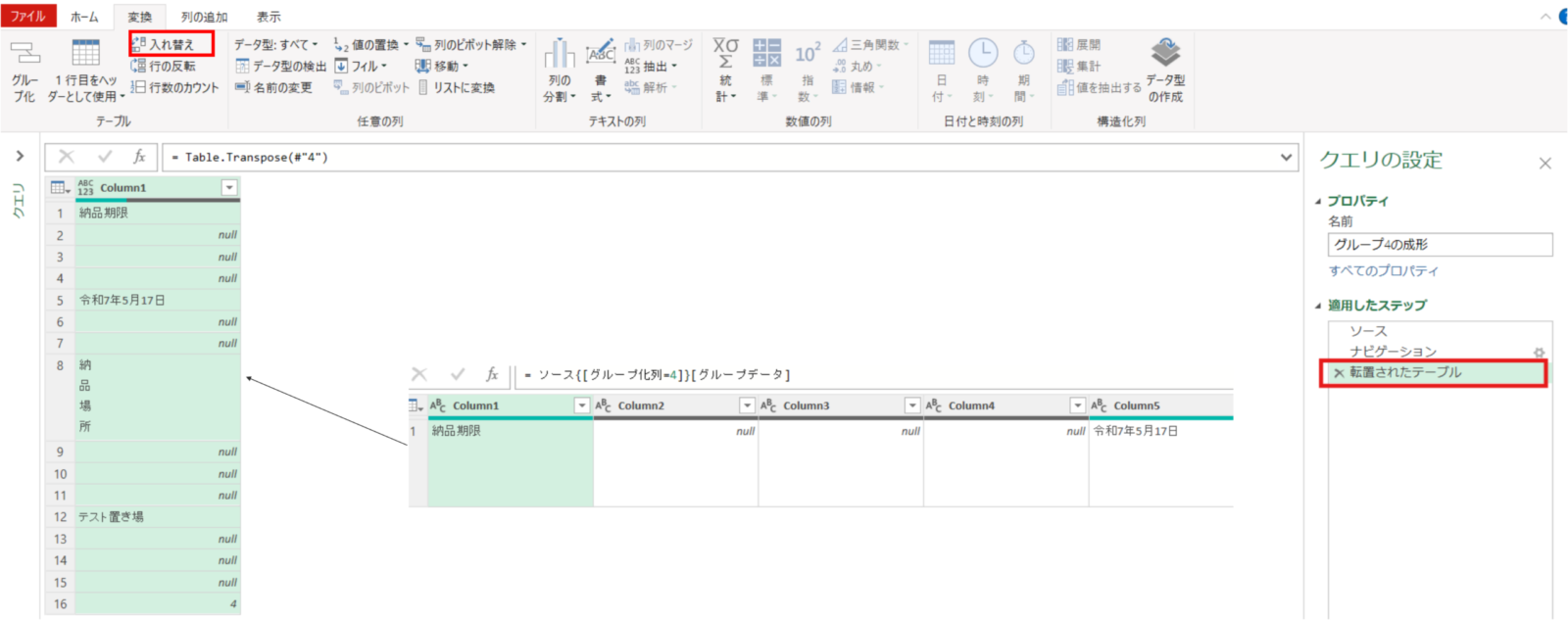
転置されたテーブル = Table.Transpose(#"4")次に列1が”納品場所”以降の行を削除するためのステップを、インデクス列を追加したやり方で実装します。このやり方を用いると、納品場所という文字がPDFによって異なる行数に出現したとしても動的に追従することができます。
- まずは列の追加タブ⇒インデックス列(0から・1からどちらでも可)を追加します。
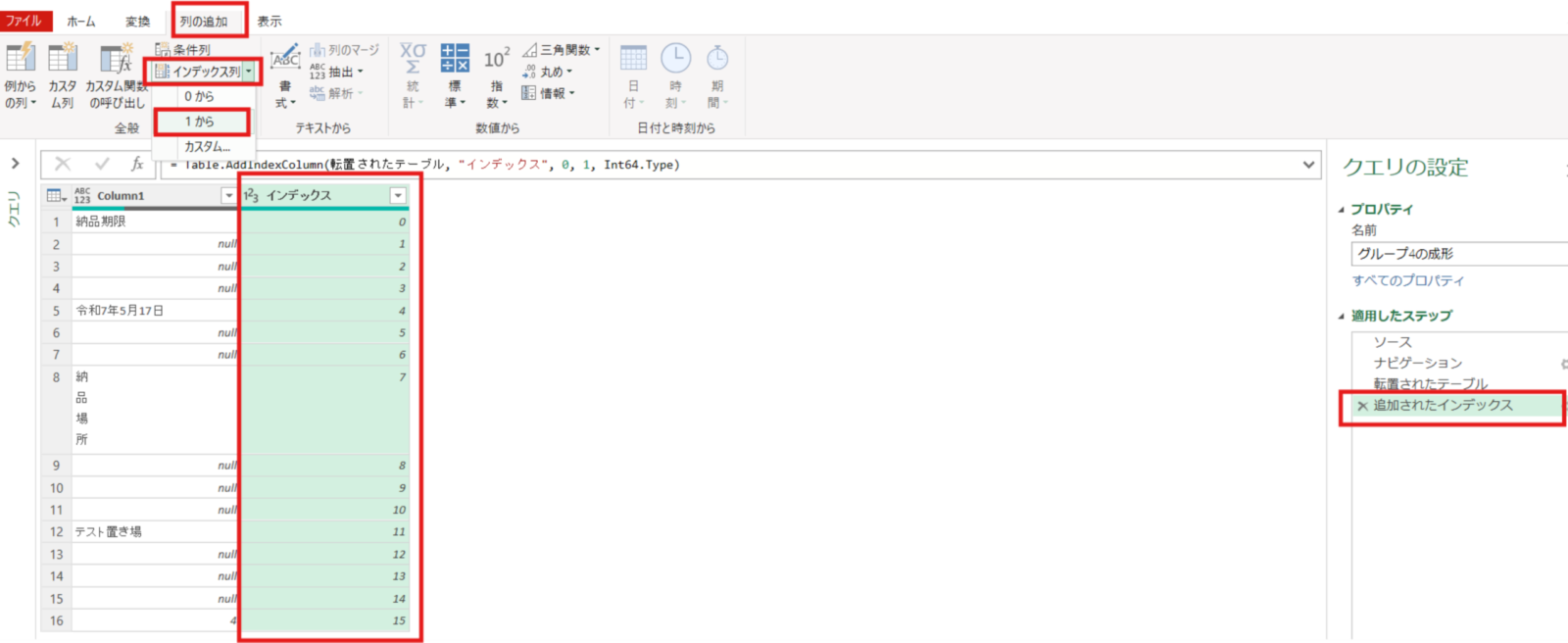
追加されたインデックス = Table.AddIndexColumn(転置されたテーブル, "インデックス", 0, 1, Int64.Type)- 一度列1基準で ”=納品場所” でフィルターを掛けます。
- 1行のみ抽出→取得された行のインデックス列の数値に対して右クリック⇒ドリルダウンを実施して、インデックス列の対象数値のみが抽出されるクエリを作成します。
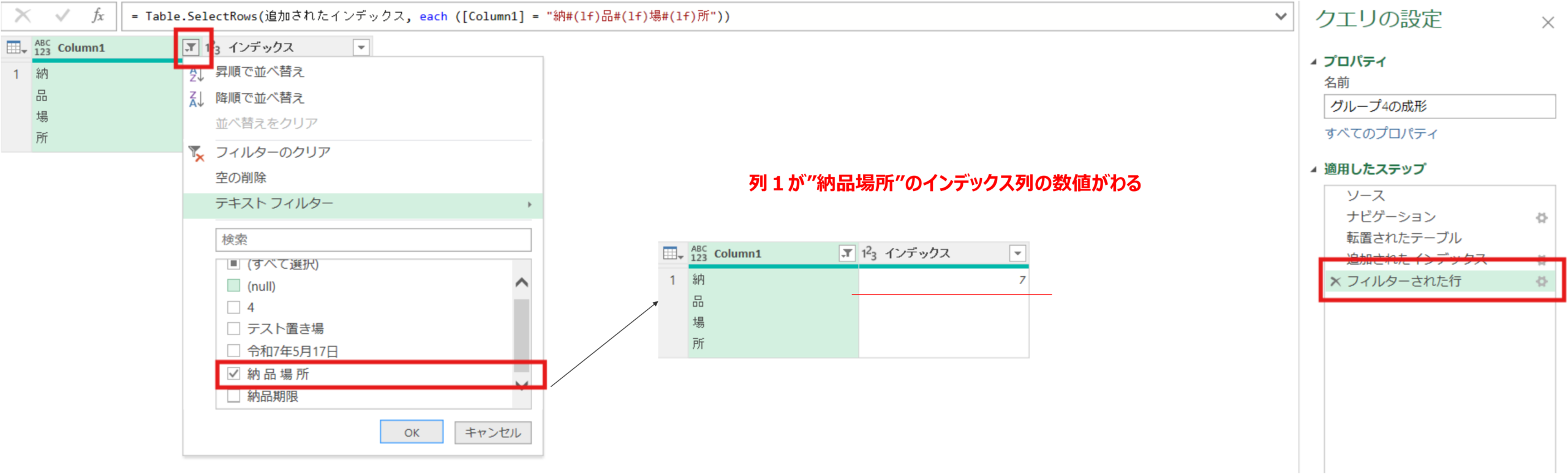
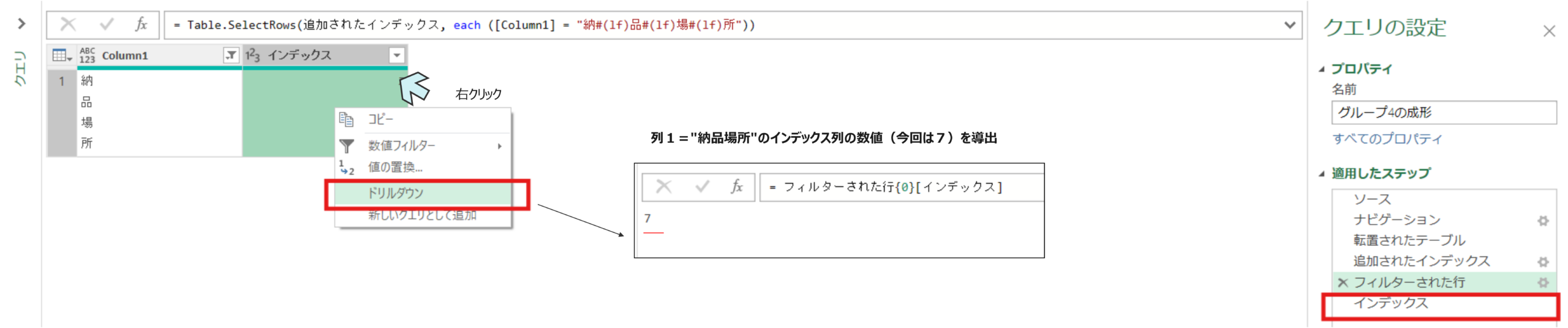
フィルターされた行 = Table.SelectRows(追加されたインデックス, each ([Column1] = "納#(lf)品#(lf)場#(lf)所"))インデックス = フィルターされた行{0}[インデックス] #⇒ドリルダウンの式- 次に以下の流れで、同じクエリステップ間の相互参照を利用して特定行数のみを保持していきます。(ちょいむずポイントです!)
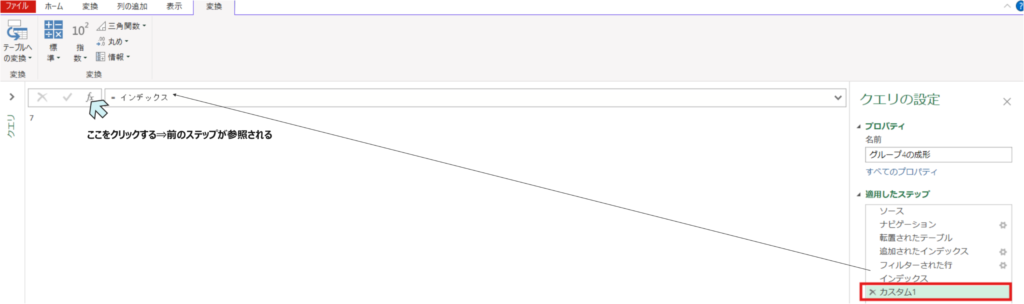
- fxをクリックしてカスタムクエリを作成する(クリックすると前のステップである、インデックスのステップが参照される)
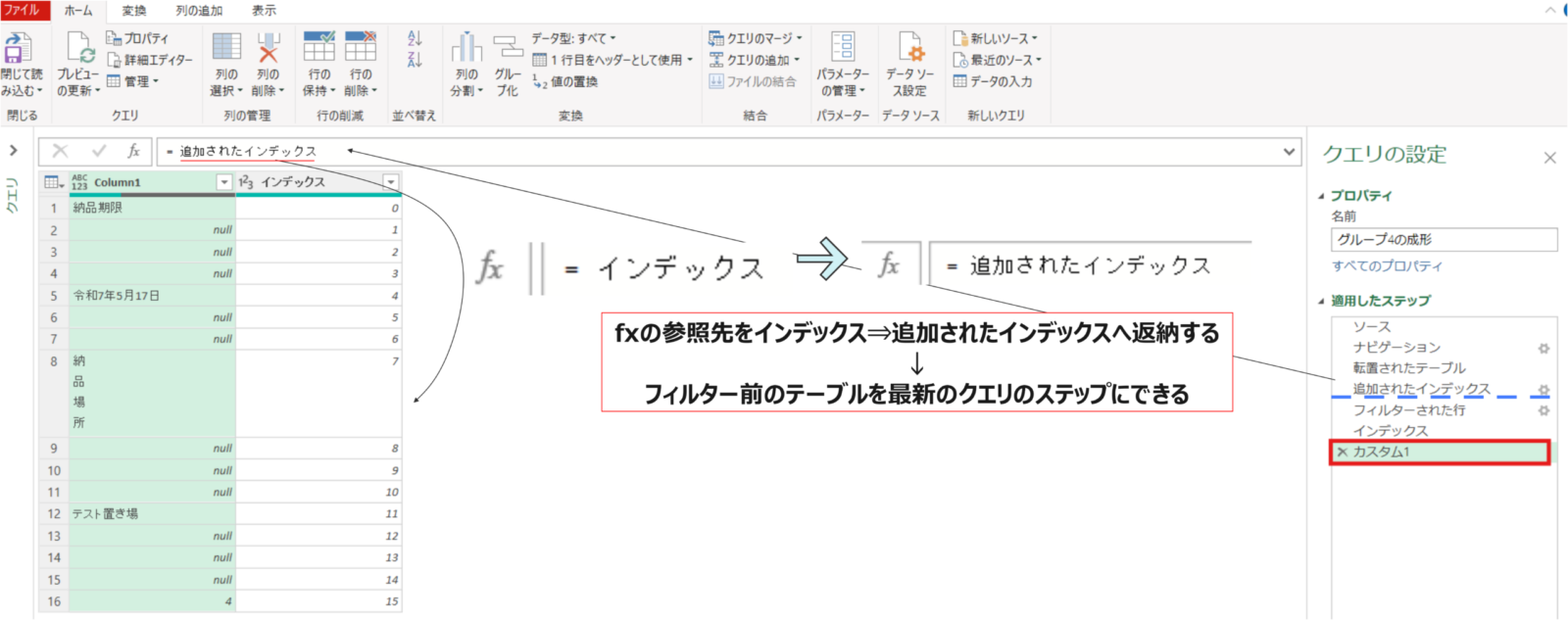
- fxの参照先を前のステップである”インデックス”⇒”追加されたインデックス”(3つ前のフィルターする前のステップ)へと変更します。これによってフィルター前のステップが最新となります。
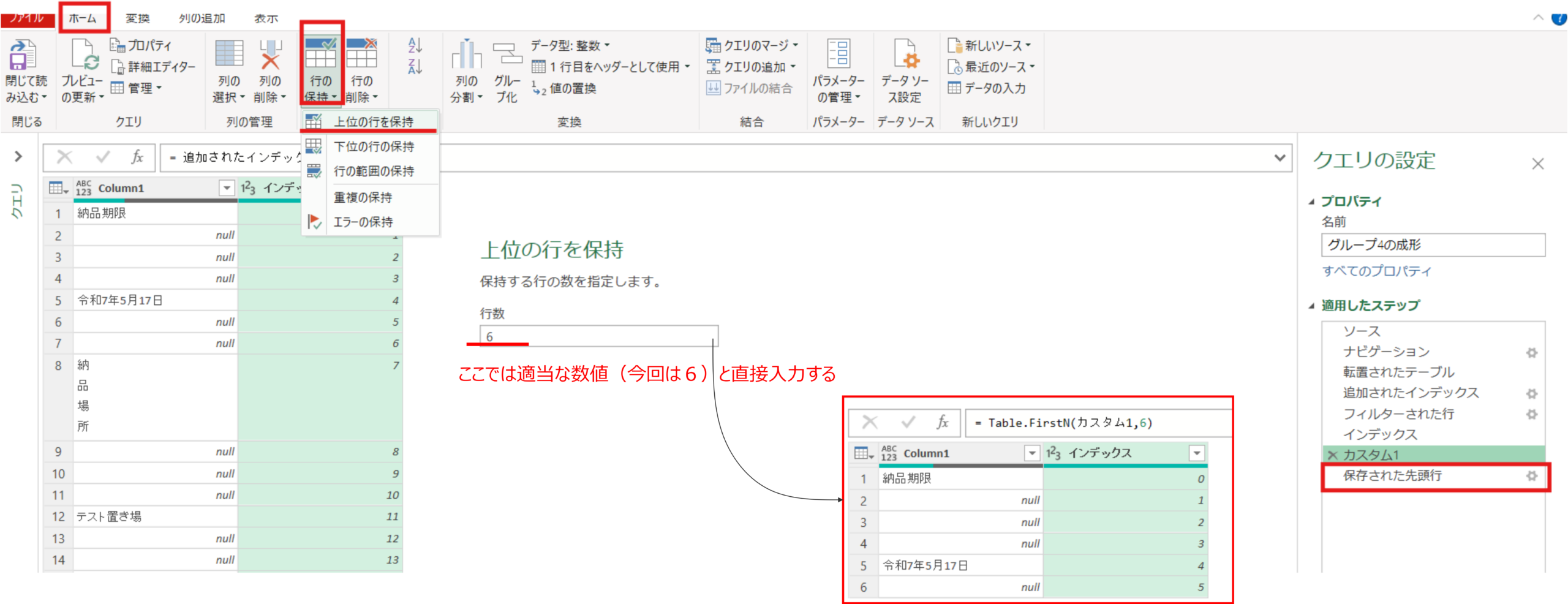
- 呼び出したステップにて上位の行の保持の操作を適用します。この際は適当な行数を入力しておきます。(写真↓では6行保持したかったので6と入力)
- 最後に、行の保持のステップのfxの関数をステップ参照を用いて変更します。やり方としては”
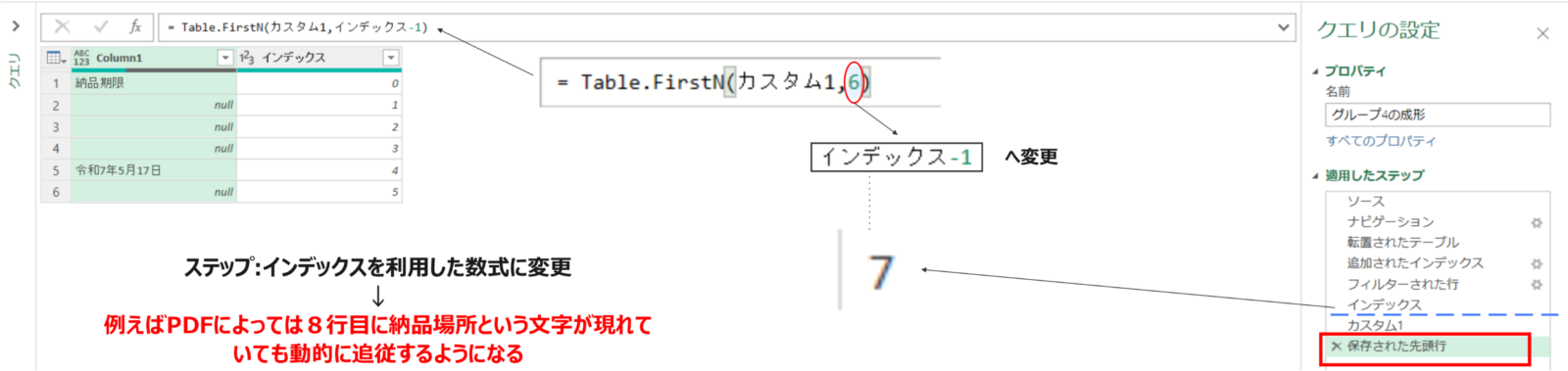
=Table.FirstN(カスタム1,6)”⇒=Table.FirstN(カスタム1,インデックス-1)へ変更することで実装。これによって列1の”納品場所”の位置が行方向で位置ズレがあっても追従するクエリとなりました。
#ポイント:手前のステップを参照して呼び出し
カスタム1 = 追加されたインデックス#ポイント⇒行数の保持の”行数”を手前のステップから参照(インデックス-1)
保存された先頭行 = Table.FirstN(カスタム1,インデックス-1)追加したインデックス列はもう不要なため削除します。
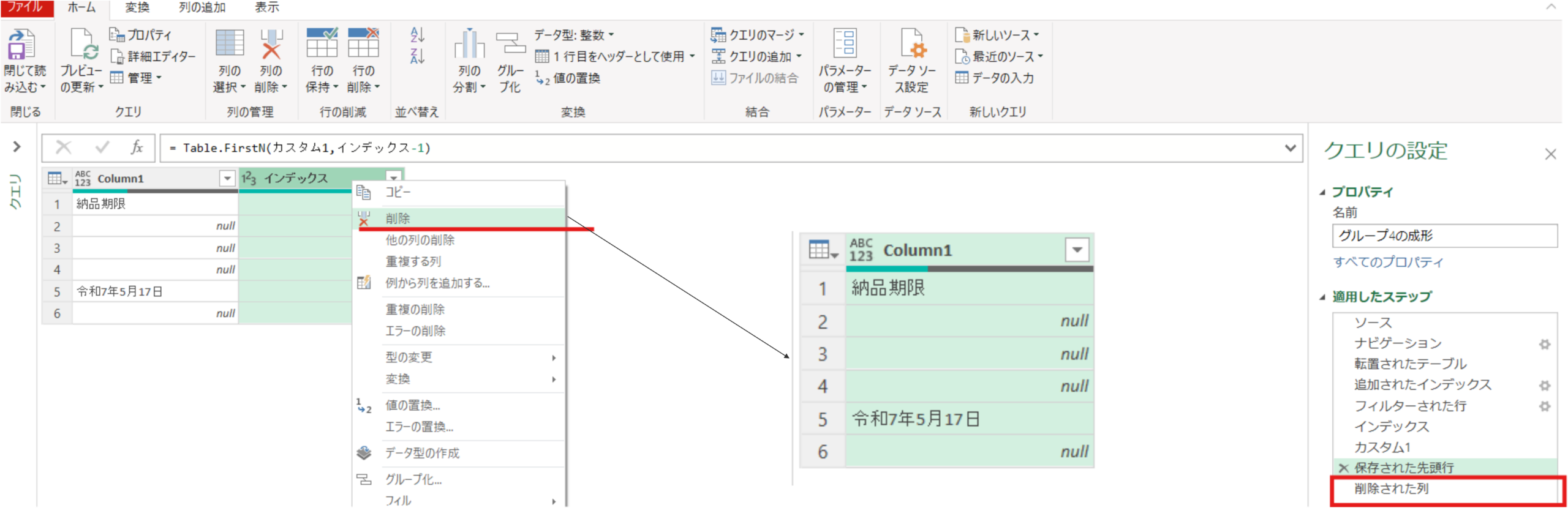
削除された列 = Table.RemoveColumns(保存された先頭行,{"インデックス"})不要な空白行を削除し、ヘッダーの昇格をさせます。
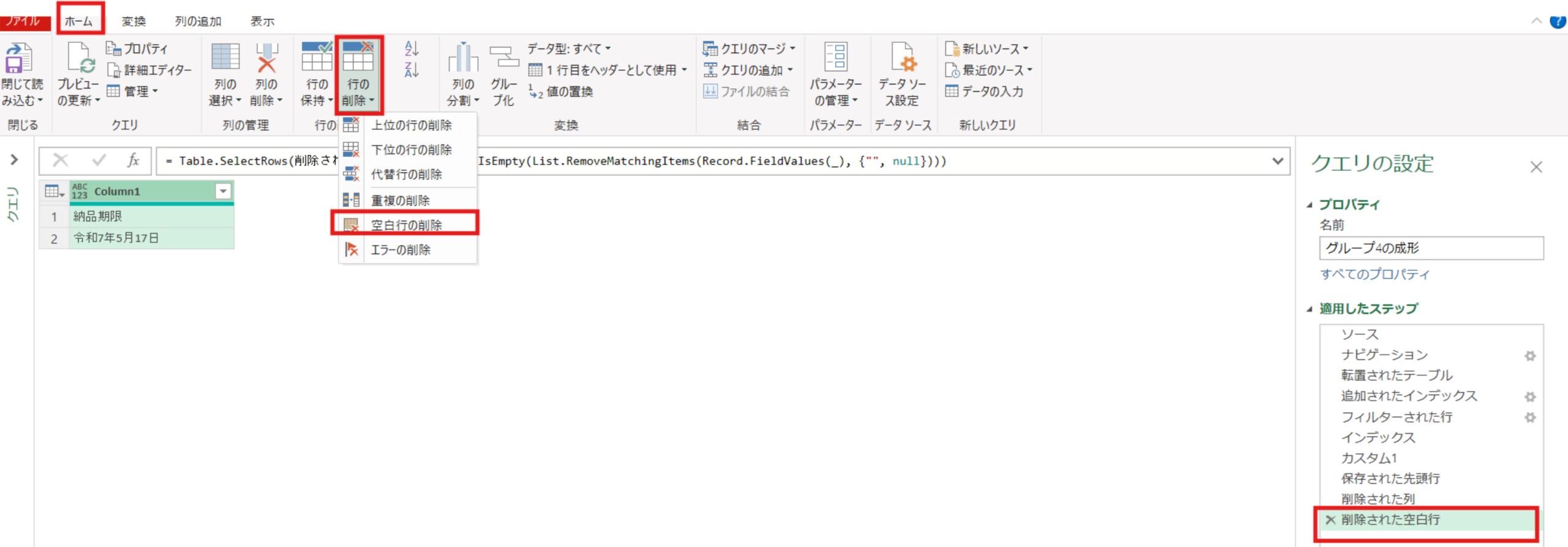
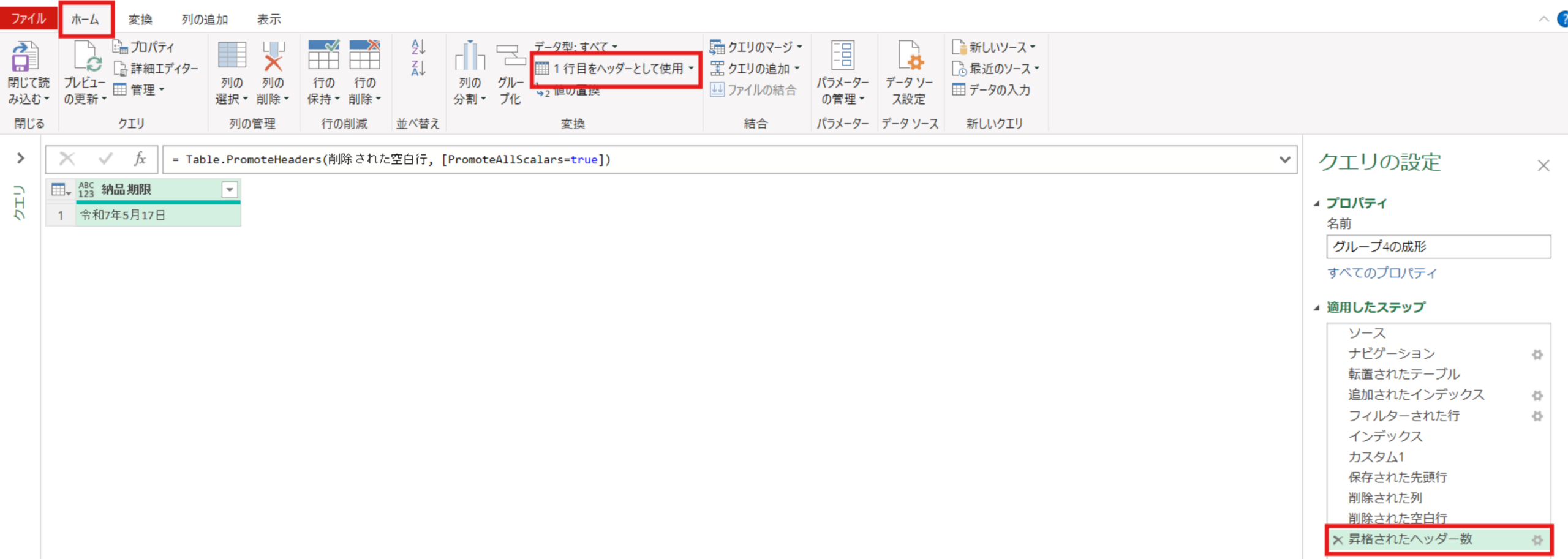
削除された空白行 = Table.SelectRows(削除された列, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))昇格されたヘッダー数 = Table.PromoteHeaders(削除された空白行, [PromoteAllScalars=true])最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。(G1~G6共通)
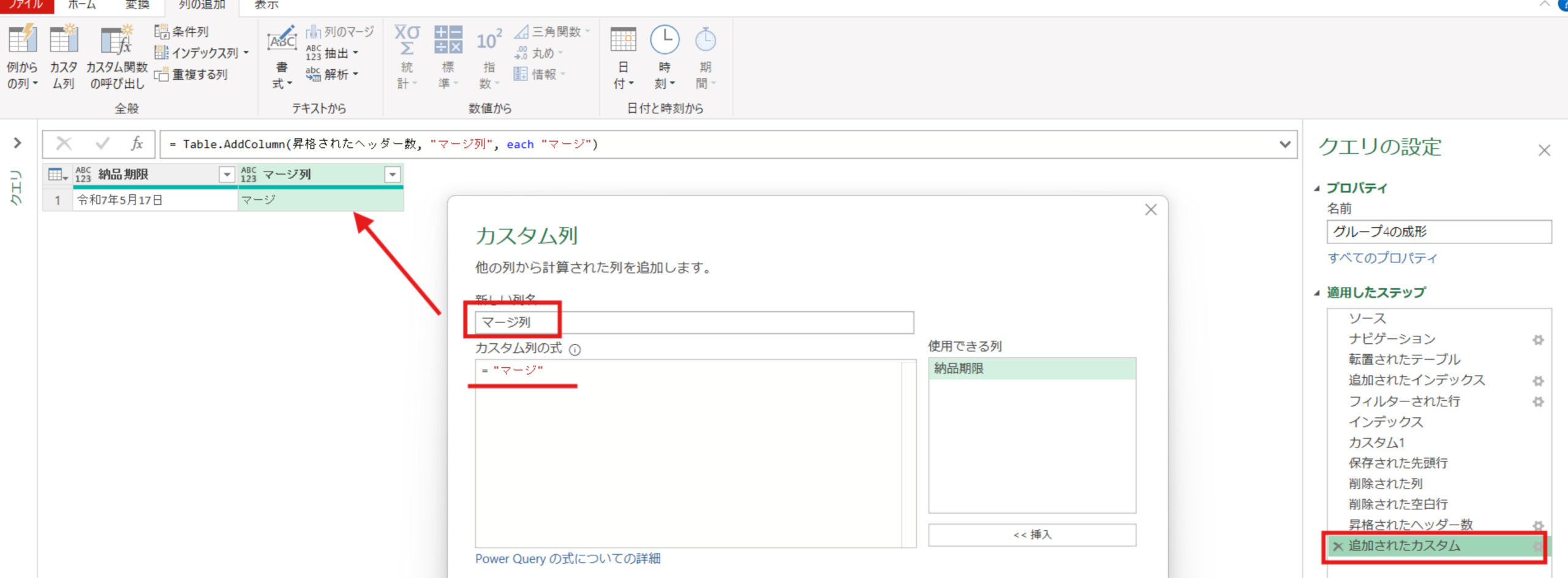
追加されたカスタム = Table.AddColumn(昇格されたヘッダー数, "マージ列", each "マージ")グループ5の整理
グループ5は商品コード含むメインのテーブルです。今回は以下のように整理を実施しました。一見整っているように見えますが、PDF毎に最初の列数が異なる現象があり複雑なステップとなっております。
まずはテーブル5をクリックしてテーブルを展開します(G1~G6共通)
ソース = PDFグループ化,
#"5" = ソース{[グループ化列=5]}[グループデータ]次に変換タブの行列の入れ替えを実施します。これは不要の列を削除を行方向でフィルターすることで実施するため、前準備になります。
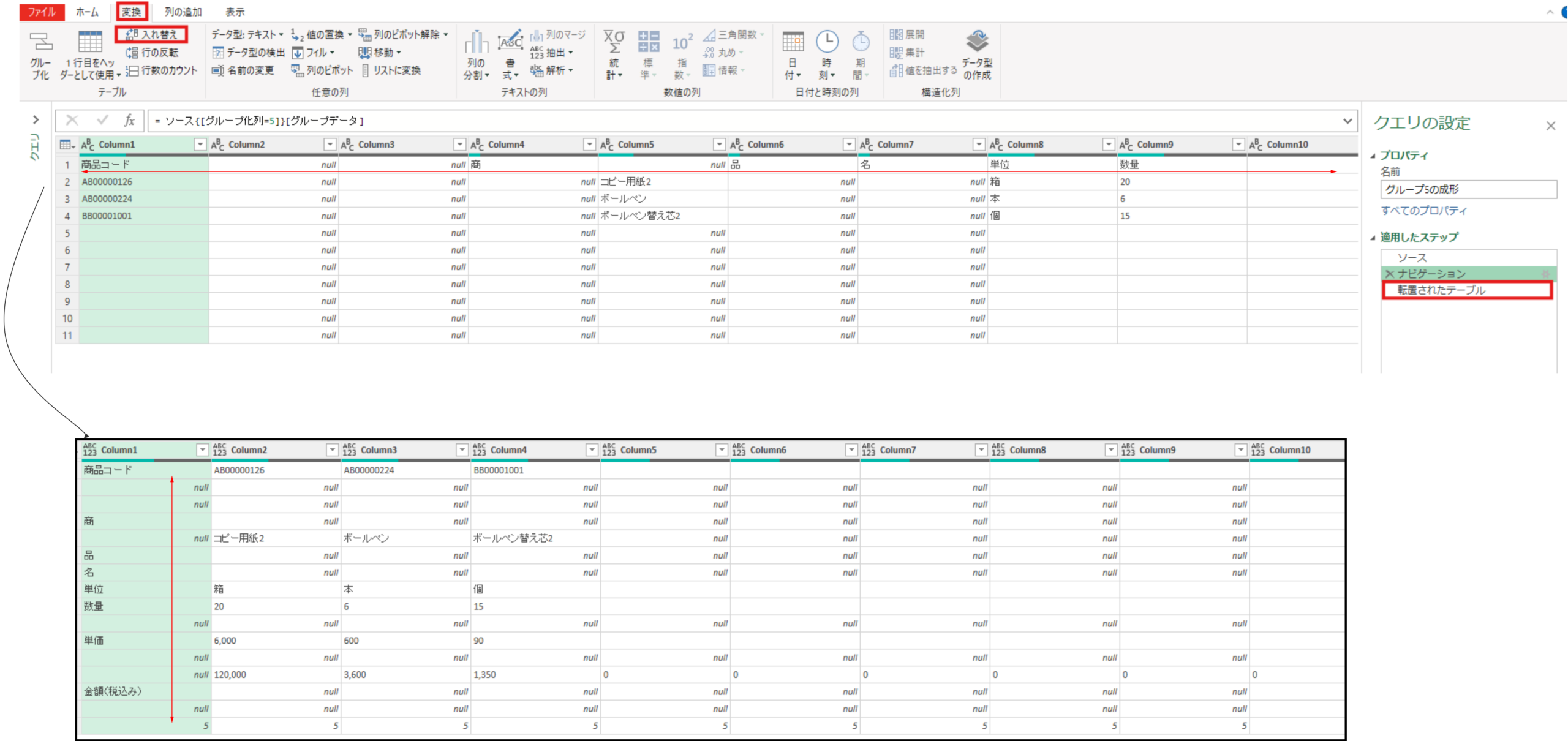
転置されたテーブル = Table.Transpose(#"5")不要な行(最初のテーブルの不要な空白列)を削除するために列2をフィルターします。”<>null”をフィルター条件にすることでnull以外保持したテーブルを取得できます。
列1でなく列2をフィルターする理由は、今回の場合1列目(元の1行目の項目行)が複数分割されてしまっており、不要行(元の不要列)を全て消去できないためです。
※フィルター後のfxの条件記載が “=**[column2]<>null”になっていることを確認しておく
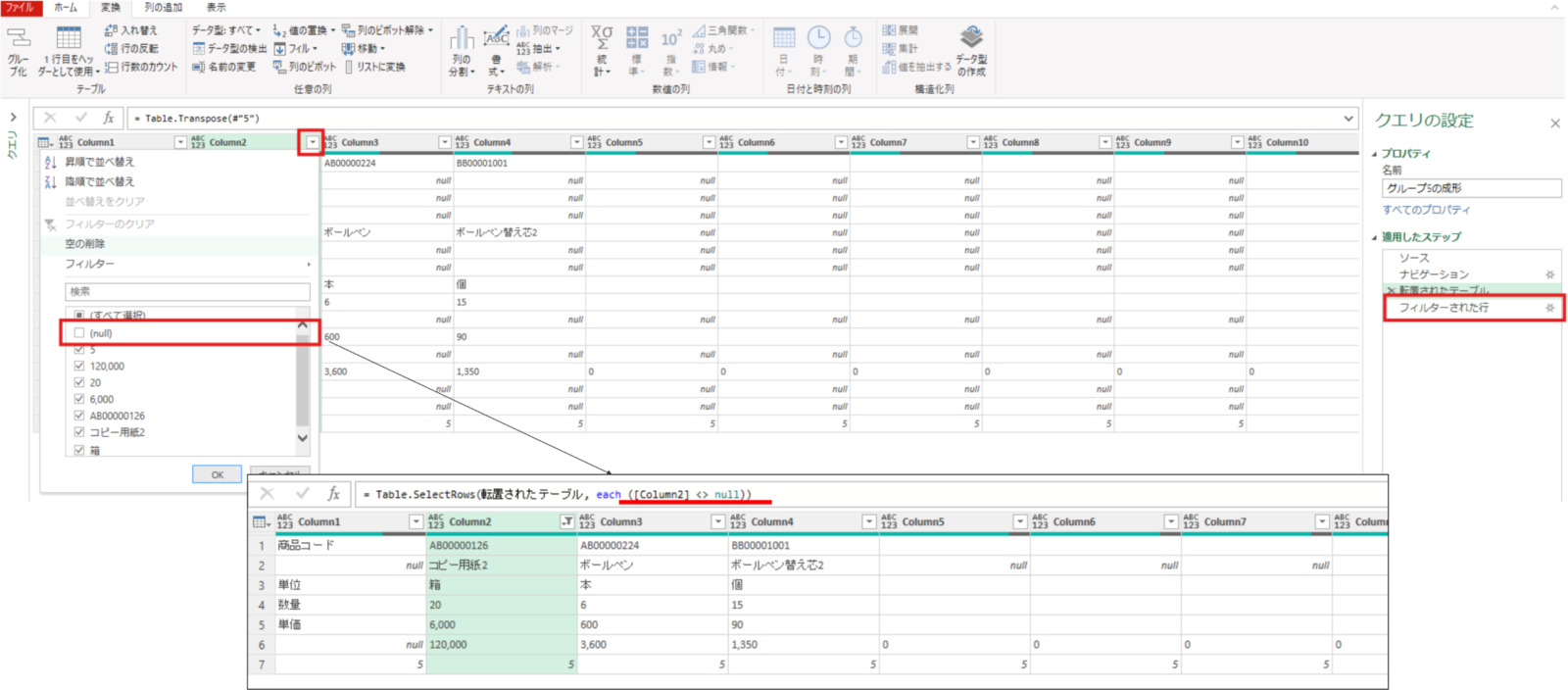
またこの状態で一番下の行(グループ番号5がある行)は不要のため一番最後の行の削除ステップで削除しておきます。
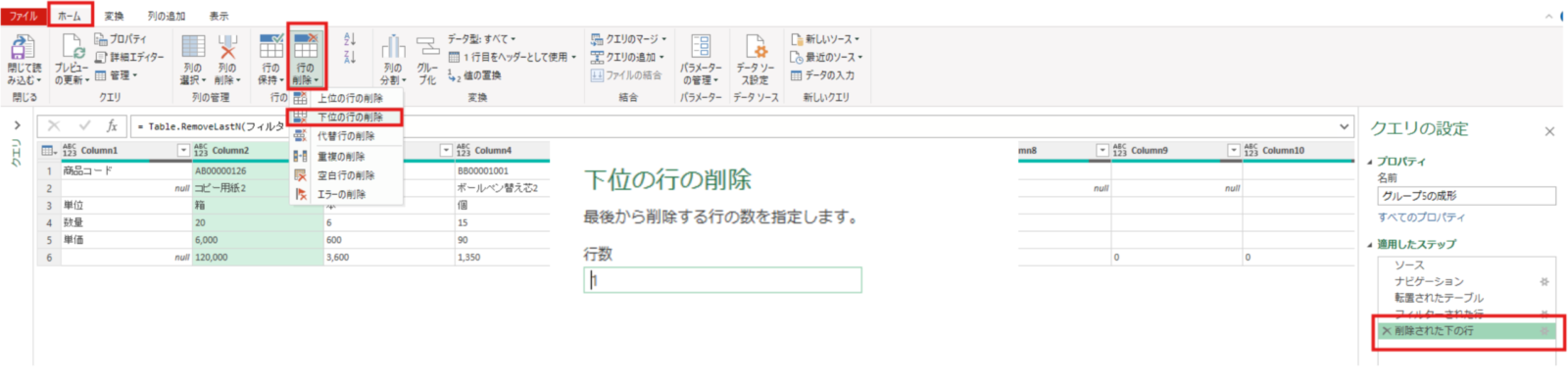
フィルターされた行 = Table.SelectRows(転置されたテーブル, each ([Column2] <> null))削除された下の行 = Table.RemoveLastN(フィルターされた行,1)不要な行(元のテーブルの列項目)が削除できたので再度行列の入れ替えをして元の形に戻します→これにより6列のテーブルになります。
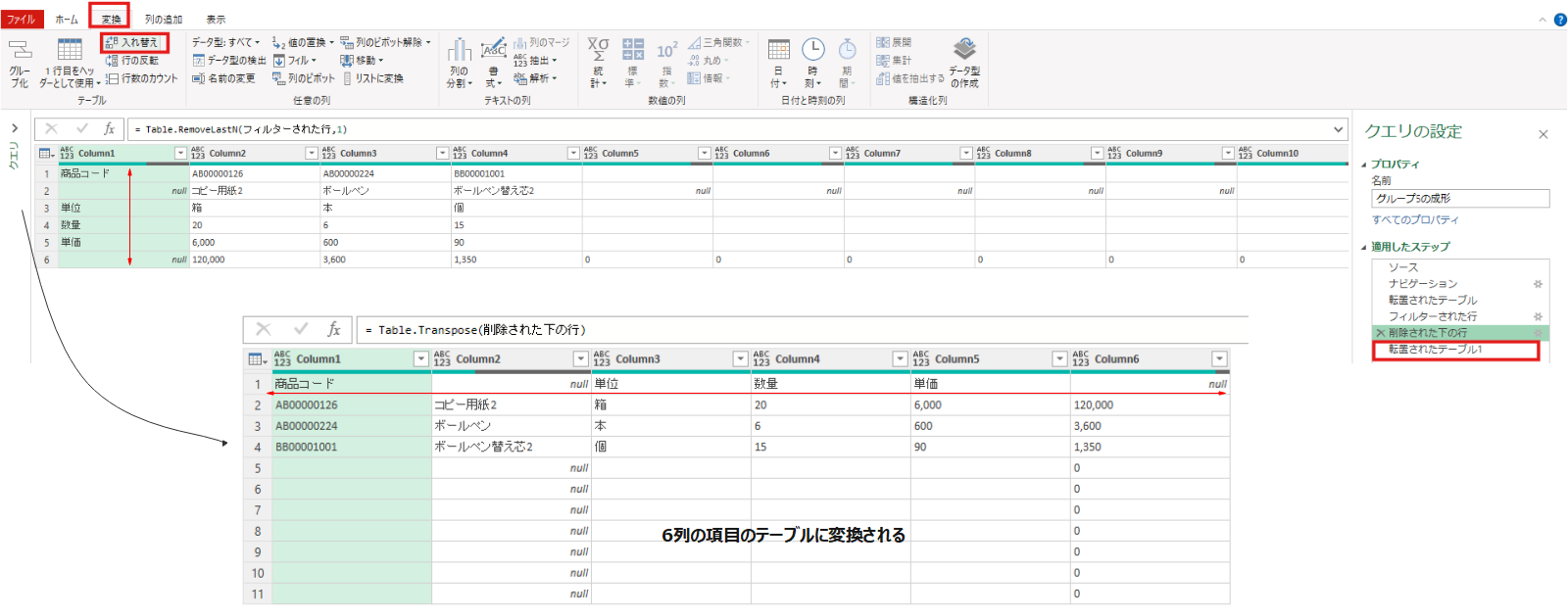
転置されたテーブル1 = Table.Transpose(削除された下の行)列1~列6の名前を手入力で変更していきます(商品コード、商品名、単位、数量、単価、合計金額)。※ヘッダー昇格が部分的に適応できないため直接入力する。

その後、1行目は不要なので上位の行の削除(1行)をします。
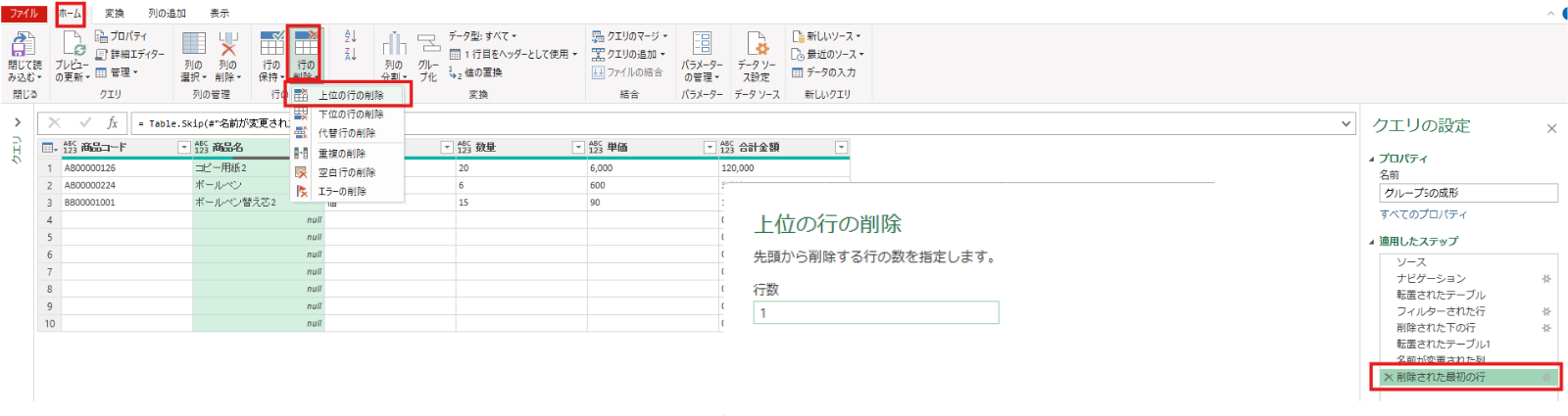
#"名前が変更された列 " = Table.RenameColumns(転置されたテーブル1,{{"Column1", "商品コード"}, {"Column2", "商品名"}, {"Column3", "単位"}, {"Column4", "数量"}, {"Column5", "単価"}, {"Column6", "合計金額"}})削除された最初の行 = Table.Skip(#"名前が変更された列 ",1)不要な空白行を削除するのですが、ここでも少し手間を加えてPDF毎の少し異なる部分を標準化(空白がnullとなっている場合とそうでない場合があるので、nullに統一させてから空白行の除去)させます。
- まず商品コード列を基準に文字置換
""⇒nullを実施します。 - 商品コード列を基準にフィルターを実施。この際null以外を選択します。この際fxの数式の末尾が ” <>null “という記載になっていることを確認してください。※そうでない場合は書き換えが必要です。
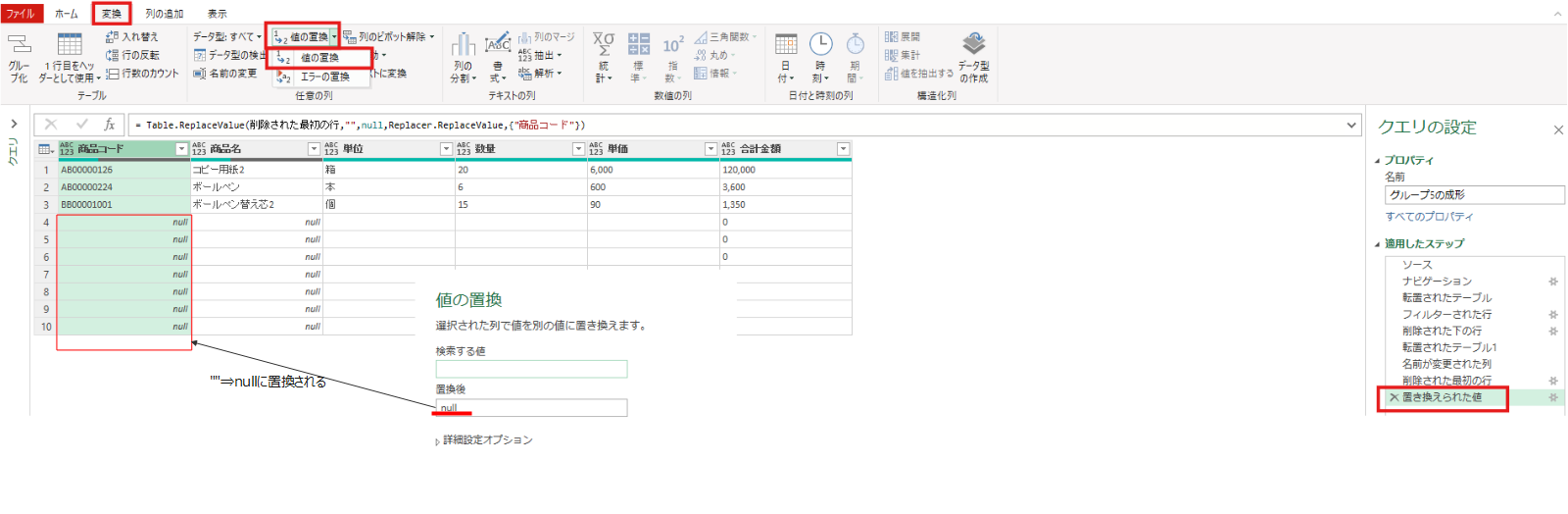
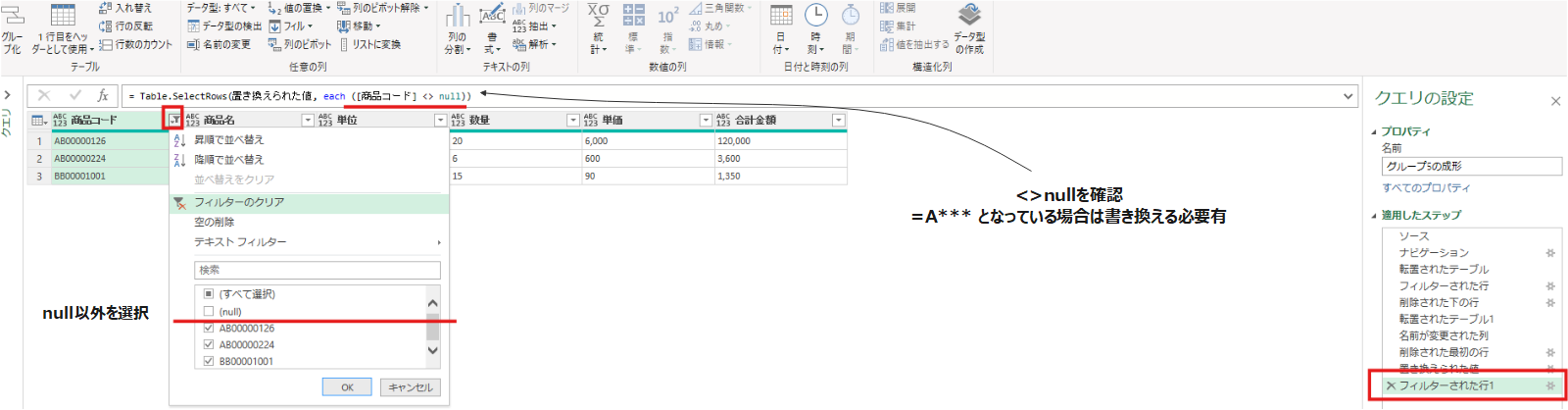
置き換えられた値 = Table.ReplaceValue(削除された最初の行,"",null,Replacer.ReplaceValue,{"商品コード"})フィルターされた行1 = Table.SelectRows(置き換えられた値, each ([商品コード] <> null))最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。(G1~G6共通)
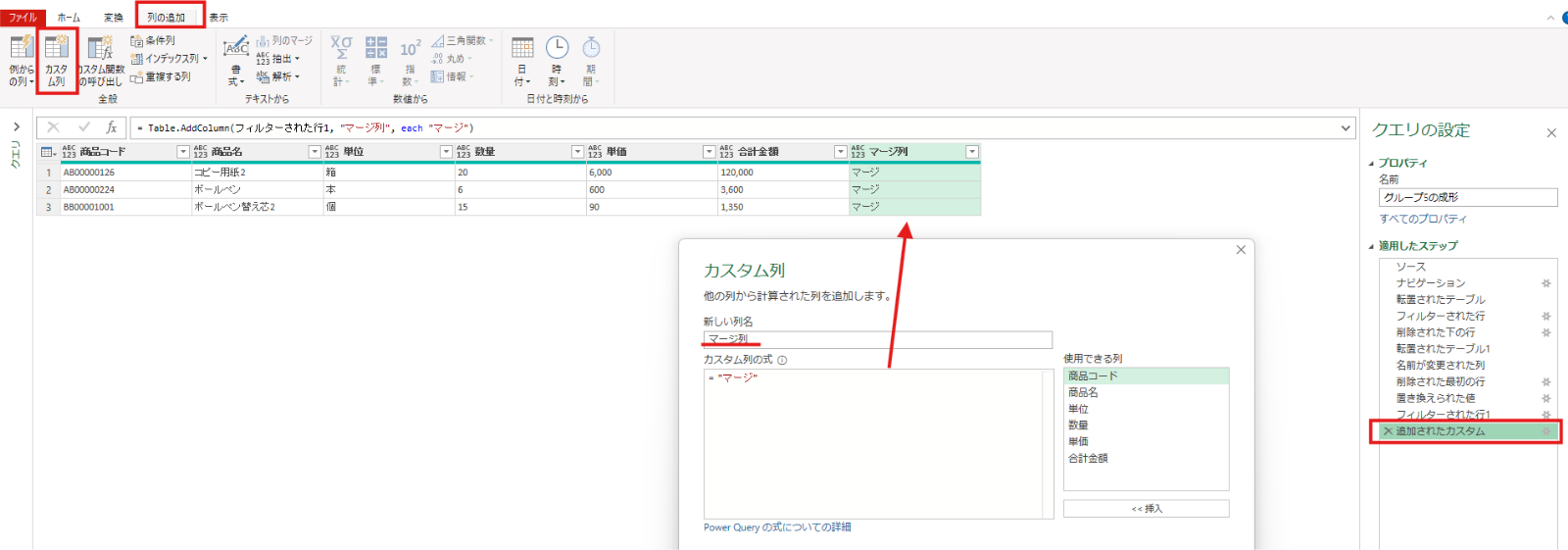
追加されたカスタム = Table.AddColumn(フィルターされた行1, "マージ列", each "マージ")グループ6の整理
以下のステップで備考を列に持つ1行テーブルへ整理しています。
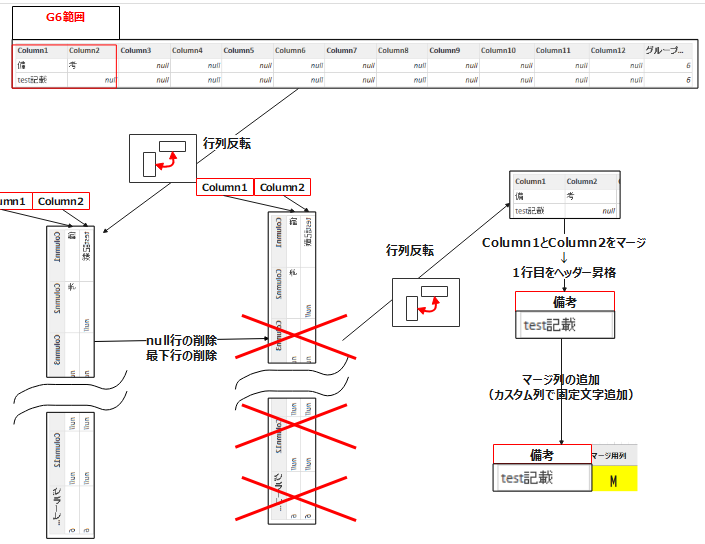
※備考文字数次第では行数が変わる可能性もあり、もう少し複雑になるかもしれません。
まずはテーブル6をクリックしてテーブルを展開します(G1~G6共通)
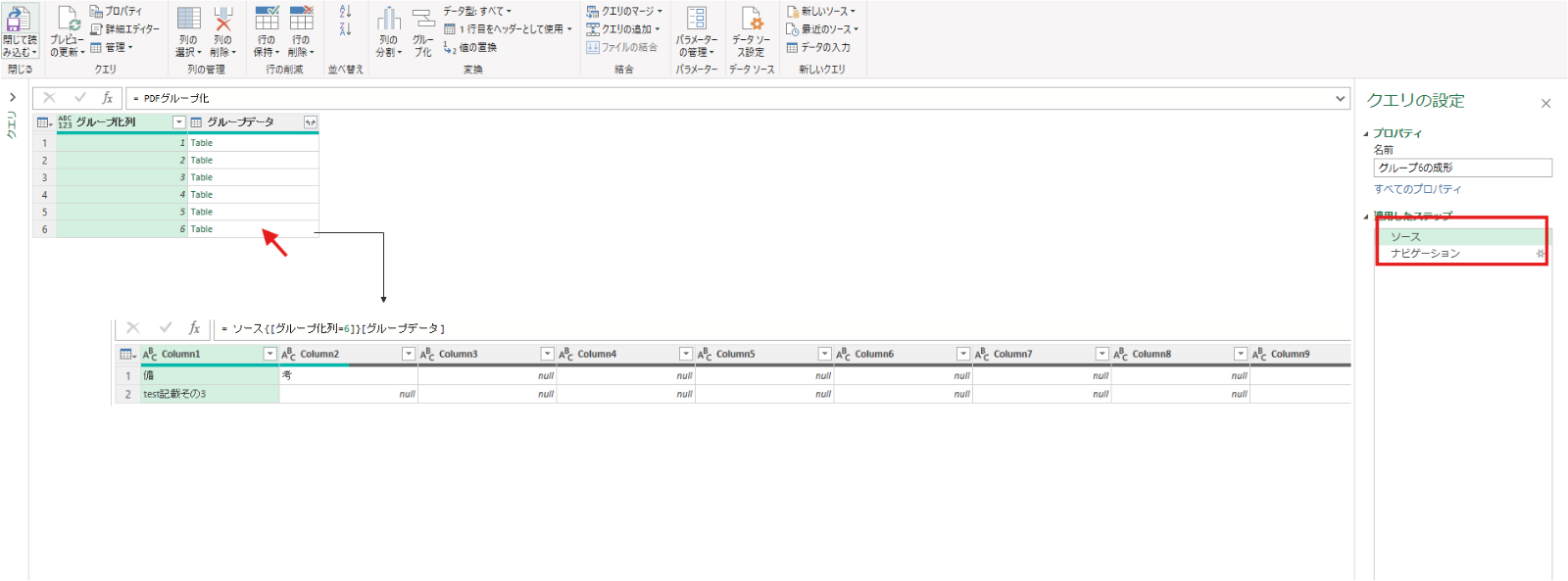
ソース = PDFグループ化,
#"6" = ソース{[グループ化列=6]}[グループデータ]次に変換タブの行列の入れ替えを実施します。(不要の列を削除を行方向で実施する準備)
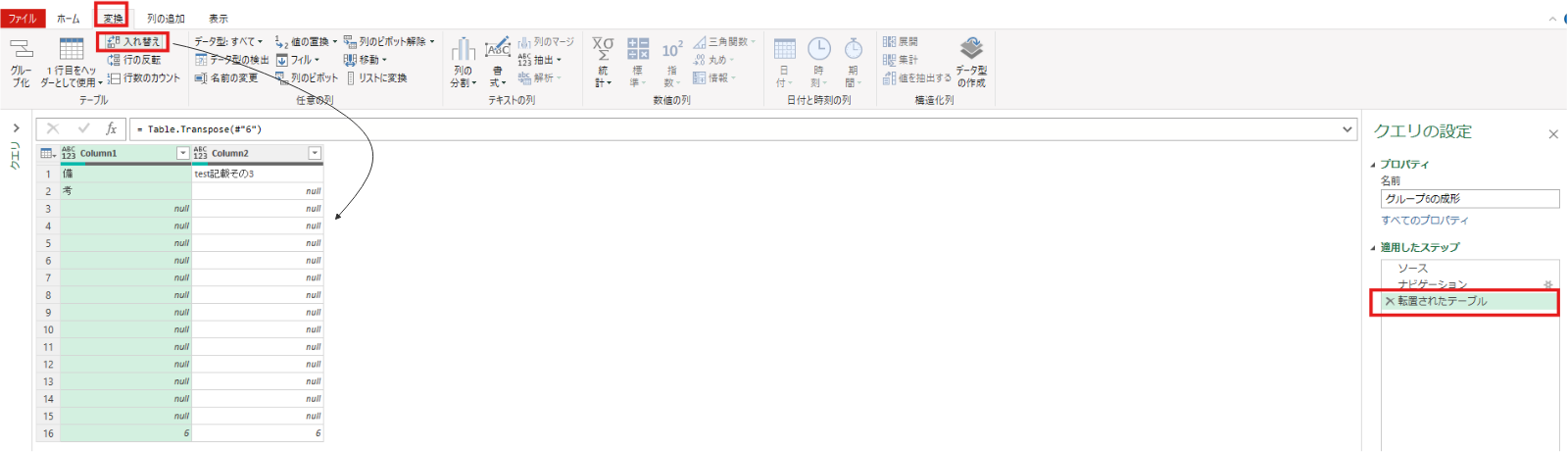
転置されたテーブル = Table.Transpose(#"6")今回不要である空白行の削除及び最後の行の削除を実施します。
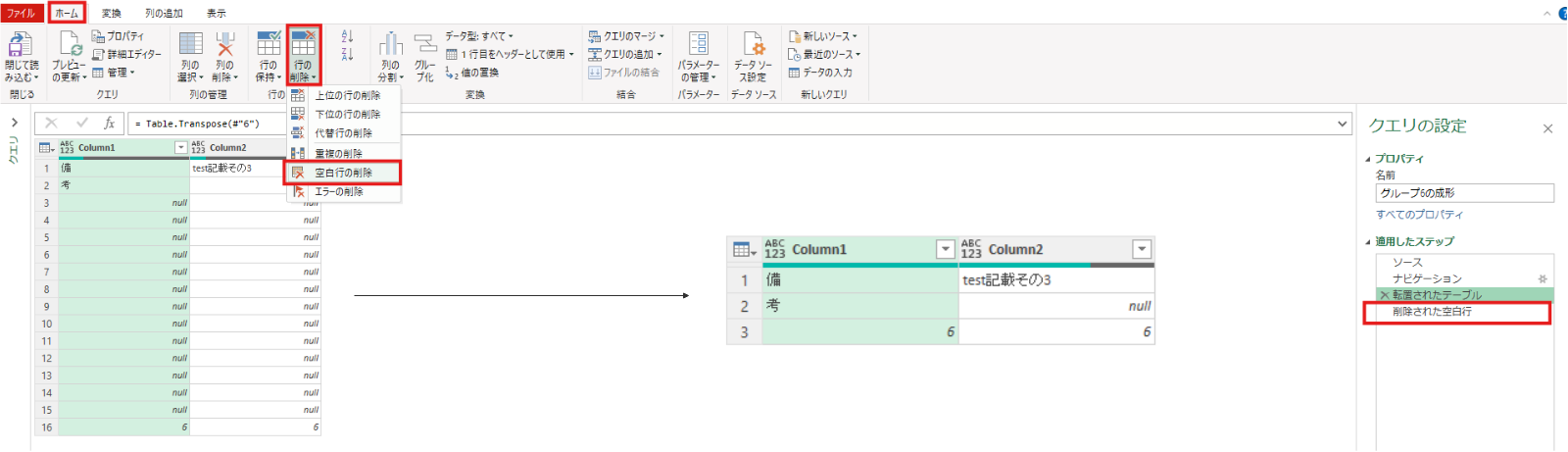
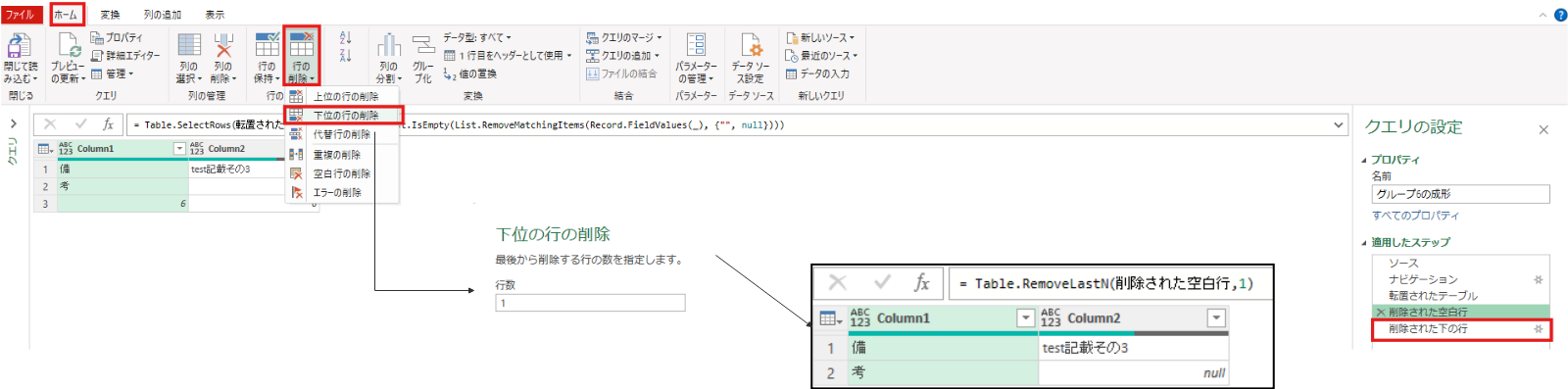
削除された空白行 = Table.SelectRows(転置されたテーブル, each not List.IsEmpty(List.RemoveMatchingItems(Record.FieldValues(_), {"", null})))削除された下の行 = Table.RemoveLastN(削除された空白行,1)再度、変換タブの行列の入れ替えを実施してテーブルを元の形に戻します。(列1と列2のみのテーブルとなっていることを確認)
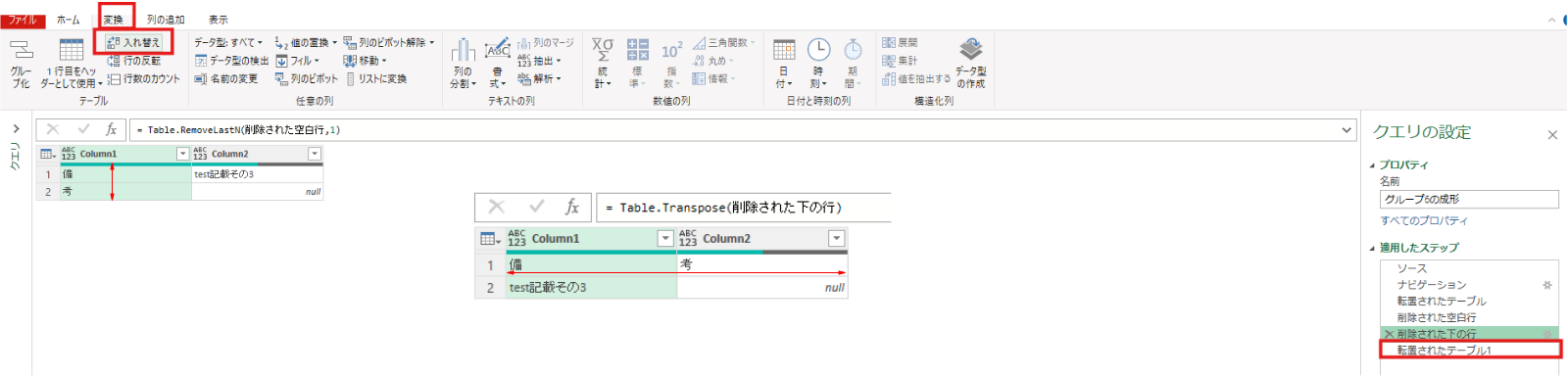
転置されたテーブル1 = Table.Transpose(削除された下の行)列1と列2をマージしたのちに、ヘッダー昇格をさせます。これによって”備考”という文字が列項目になります。
その後、1行目は不要なので上位の行の削除(1行)をします。
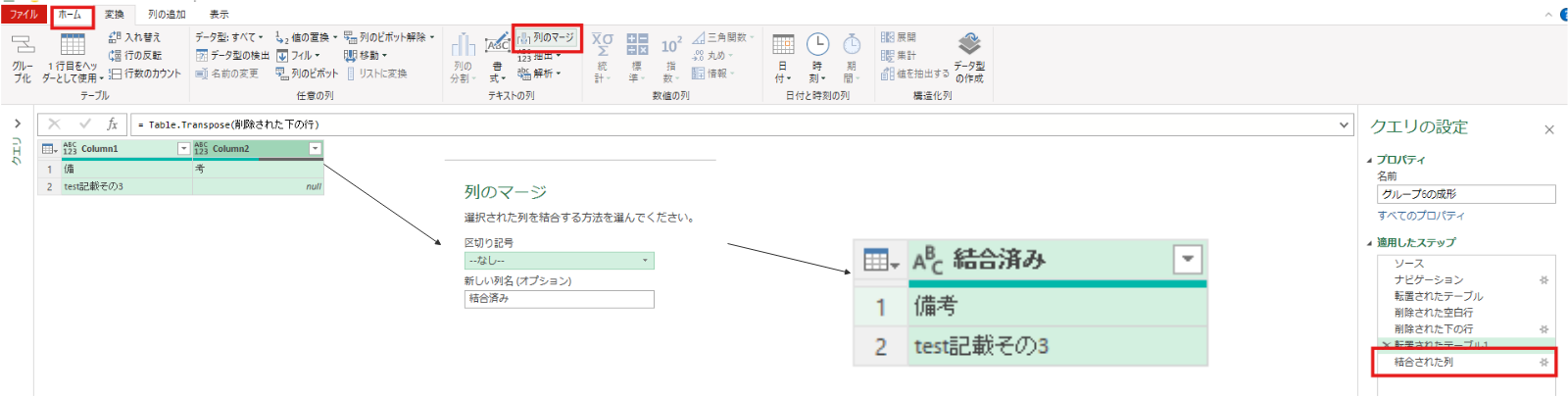
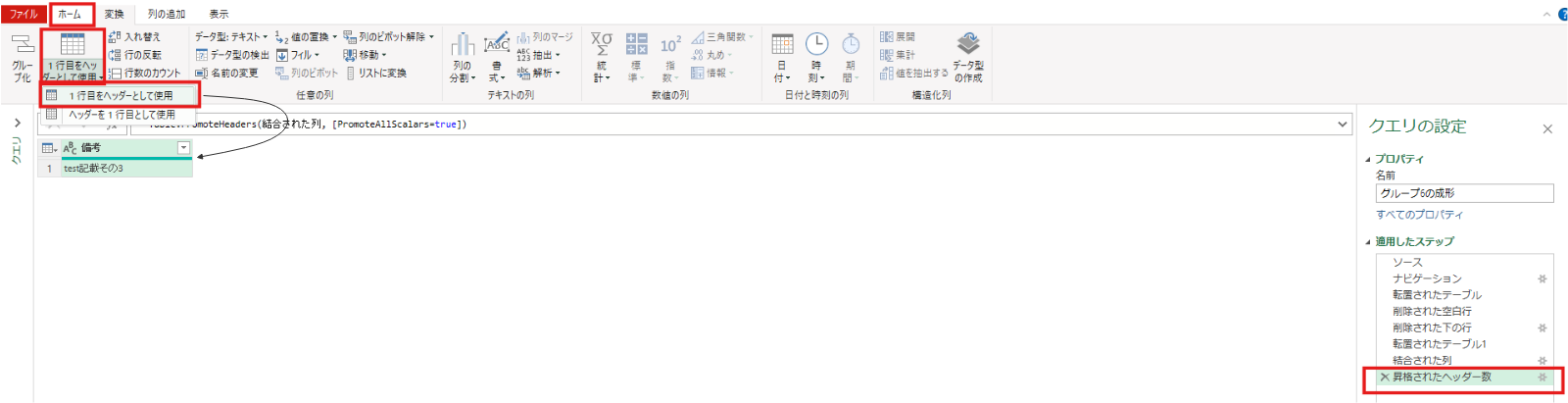
結合された列 = Table.CombineColumns(転置されたテーブル1,{"Column1", "Column2"},Combiner.CombineTextByDelimiter("", QuoteStyle.None),"結合済み")昇格されたヘッダー数 = Table.PromoteHeaders(結合された列, [PromoteAllScalars=true])最後に、列の追加タブ⇒カスタム列で”マージ”という文字を全ての行にもつ[マージ列]という名前の列を追加しました。(G1~G6共通)
追加されたカスタム = Table.AddColumn(昇格されたヘッダー数, "マージ列", each "マージ")整理ポイント抜粋
列を直接操作する際は注意が必要
PowerQueryでは複数ファイルで同じ整理ステップを適用する際に、以下のようなファイルによって列の位置がずれているパターンは注意が必要になります。極力このようなデータは作らないことがベストですが、今回利用したPDFではこのような不整合が発生しました。
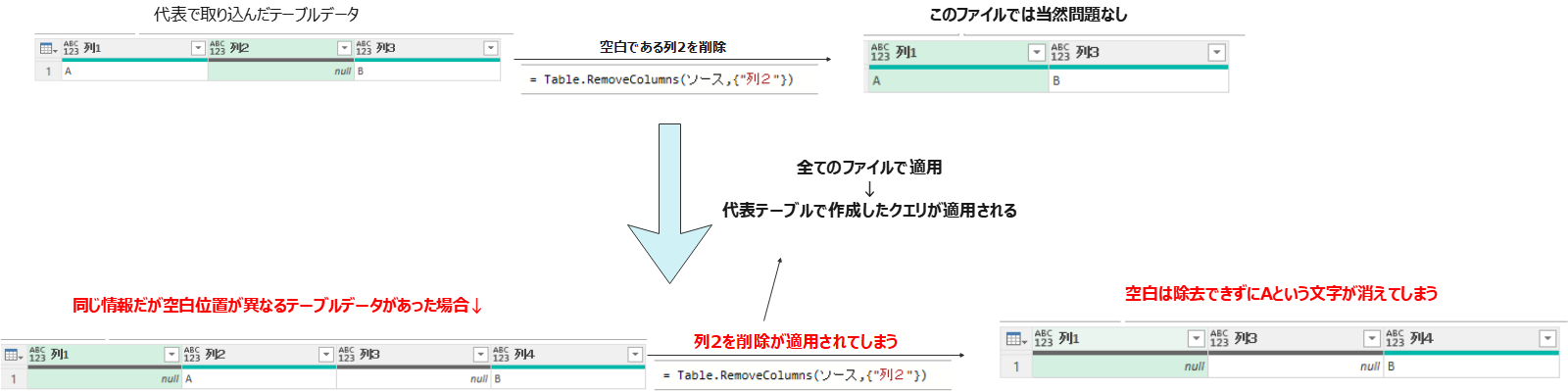
列名を直接指定した操作(削除や名前の変更、その他色々な列指定操作)は確実にその列が全てのデータで同じ場合に適用する必要があります。
今回は以下のような場面で列名操作の不具合を回避しています。参考にして下さい。
- 基本的に全てのグループにおいて空白の不要な列を削除する時は一度行列の入れ替えを実施⇒空白行の削除⇒元に戻すで対応実施
- グループ5において各テーブルの列位置がずれていた時も、一度行列の入れ替えを実施⇒入れ替え後に確実に存在する列2(入れ替え前の2行目)を基準にフィルターを実施して、不整合な行(入れ替え前の不要な列)を除去⇒再度入れ替え実施
- 列のマージを実施するときは、1や2のやり方で確実に列数が整っている状態にしてから実施
クエリ参照を利用して変化する数値情報などに対応する
PowerQueryでは他のクエリの参照が可能です。これは同じクエリ内(手前のステップ)でも同様です。また前提として、PowerQueryではfxに記載されるステップごとの数式を元に整理が実施されており変数としてデータが格納されています。そして基本的には前のステップを参照した形で操作していきます。
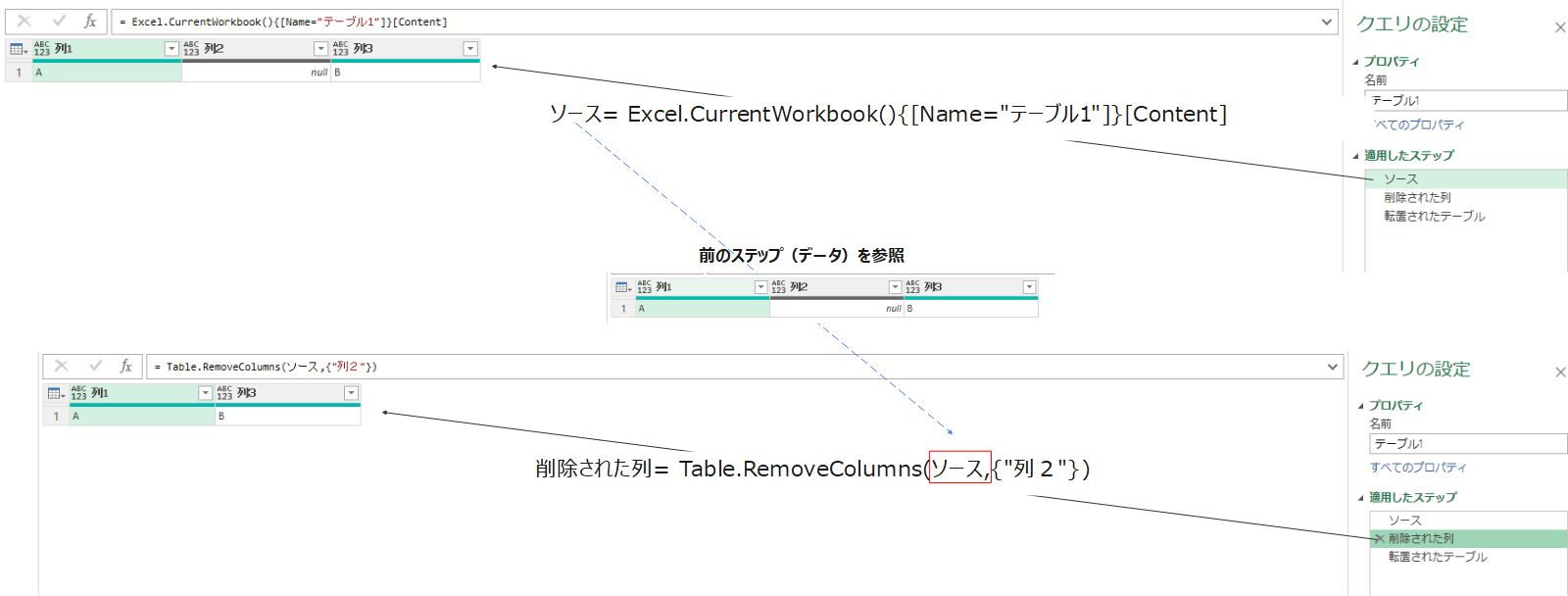
そのため、カスタムステップを作成して、前のステップや、前の前のステップを呼び出した操作を作成できます。
今回はグループ4にて、特定の文字がある行数が変動する想定でクエリの参照を利用しました。是非参考にして下さい。
- インデックス列を追加、ある列の特定文字をフィルターする
- 1のインデックス列をドリルダウンして、対象の行数値が入ったステップとして保持
- インデックス列を追加したステップを参照(クエリの参照1)
- 3のデータに対して行数保持のクエリを適用する際に2のクエリの数値を利用(クエリの参照2)
色々考えることが多いんだね。とりあえず列削除等、列をむやみやたらに直接操作したら駄目なことは感覚として理解したよ。あとクエリの参照も便利そうだね!
はい。本来同じデータを整理する際はさほど気にする必要はないのですが、思いがけないデータの不整合があった際は、列操作で不具合が起きている可能性が高いです。クエリ参照含め、細かい操作技術は別記事で改めて纏めたいと思います。
まとめ:PowerQueyでの注文書PDFファイルのグループ別整理を詳しく解説
本記事では以下の内容に絞って説明しました。
- PowerQueryのPDFファイルのグループ別(1~6)の整理ステップについて解説。ポイントとしては以下です
- 整理する際に列を直接指定する操作はファイルによっては不整合を起こすため、行列入れ替え⇒行方向で処理実施⇒元に戻すなど、ちょっとした工夫がいる
- クエリのステップ間を上手く参照することで、変動する数値を指定したいときなど、細かい操作に対応できる
長くなりましたが以上です。次回は今回整理したグループ(1~6)の結合とステップを関数化する手順について説明します。
以上、マー坊でした!。

コメント