お待たせしました。前回の整理ポイントを踏まえて今回からはPowerQueryでの実操作に入っていきます。
今回は、前回のPowerQueyでの操作イメージを踏まえて実際のPowerQueyでの操作に入っていきたいと思います。
尚今回のテーマはPDF注文書データを一例に、PowerQueyを用いた複雑な構造データの集計技術やその後の応用事例を学ぶことを目的としています。↓
- 電子PDFをPowerQueryで集計・成形する流れを知ること
- 少し複雑な構造のデータをPowerQueryで成形する際の考え方やテクニックを学ぶこと
- PowerQueryで集計したデータをexcelで取り扱う事例を学ぶこと
本記事(#2)からは実際にPowerQueyの処理をしていくことで集計ツールを作成していきます。今回は
- PowerQuey処理データのグループ分けについて
の内容に絞って進めていきます。
- 複雑な構造のPDFファイルなどをPowerQueyで整理するために必要なグループ化の流れ
- 実際にPowerQueyでグループ化するステップ操作(マウス操作やM言語)について
PowerQuery の全体フローと今回の焦点
いよいよだね!!
前回はPowerQueyでの処理流れの整理をしたけど、この前準備で完璧にできるのかな?
実操作についても簡単にまとめていきましょう。結構長いステップになりますが、小分けにすれば必ずできるようになります!!
今回はまず初めに実施すべきグループ化に焦点を当てて説明していきます
今回のPDFデータは以下のような形のものでした。これを目的のテーブル形式に成形⇒全てのPDFで結合してデータベースとして纏める⇒検索などで利用することが目標でした。

これらを実現するためのPowerQueryでの操作の流れが以下①~⑩になります。後半はカスタム関数を多用するため多少難しいと思いますが、この流れが掴めれば多くのPowerQuery自動化に対応できると思います。今回はまず初めのステップである①と②のグループ化について纏めました。
PowerQueyでの処理データグループ化・グループ別の手順
今回は ①まず1ページ取り込んで画面把握をする ②取り込んだページのパーツ分け(グループ化の操作)について説明していきます。
まずは1ページ取り込んでみる(どんな画面か把握する)
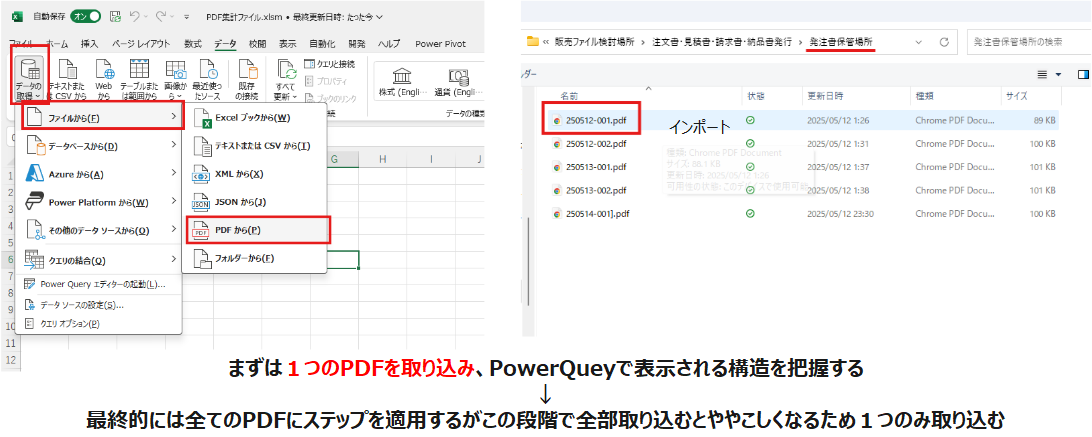
早速excelを開き・データタブを選択⇒データの取得⇒ファイルから⇒PDFから を選び対象ファイルをエクスプローラー画面より選択することでPDFファイルをインポートしてみましょう。
(本来であれば全てのPDFファイルに対して適応するために、全てのPDFを取り込み⇒処理する仕組みが必要ですが、ややこしくなるのでまずは1枚のPDFに対しての手続きを作成することにします。)
この後以下のようなナビゲーション画面に遷移されますが、今回はTableデータは無視して、Page**とあるデータを対象としてPowerQueyエディターで編集していくため以下のように操作します。
※実際にはこの処理は後々変更可能です
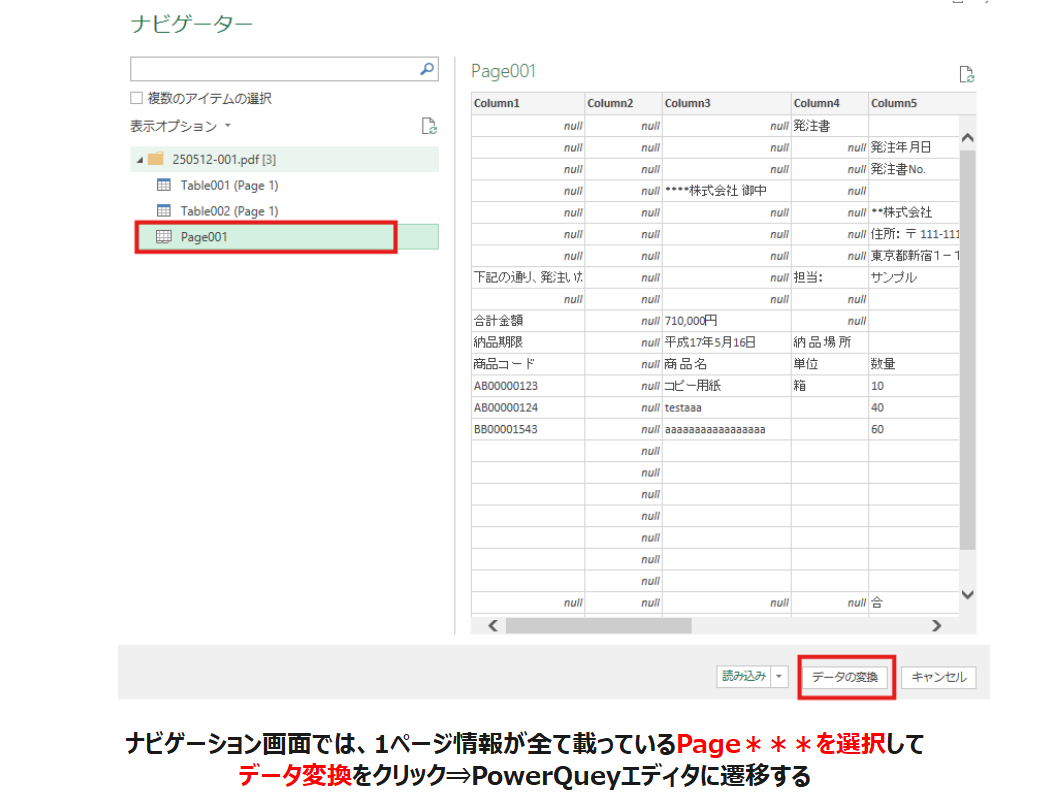
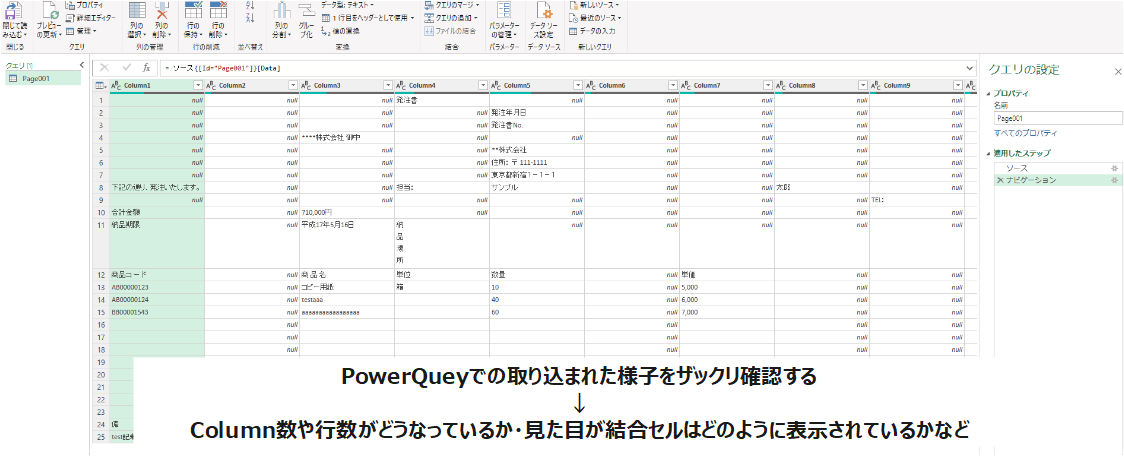
上記ナビゲーションにより以下のようなPowerQueyエディター画面に遷移されます。この画面をざっくり把握しておきましょう。以下の1と2は今回のポイントです。次のステップで詳細を見ていきます。
- 列の構造(欲しい情報が何列目~何列目に存在するか・グループ分けしたい列など)
- 行の構造(欲しい情報が何行目~何行目に存在するか・グループ分けしたい行など)
- セル結合情報がどのように分散されたかなど(excelデータを取り込んだ場合は確認必須)
取り込んだページのグループ分け(グループ化)を実施する
処理毎にデータをわけるっていうのは理解できるんだけど、PowerQueyでどうやるのか全くわからないよ・・・
そこまで難しく考えなくて大丈夫です。 ①行ごとにグループ番号列を追加 ②グループ番号別にグループ化 の2ステップで簡単にグループ分けすることができます。
おさらいですが、今回は以下のようにグループ別にPowerQueyで処理を行った後にそれぞれのデータ纏めることで一つのテーブル形式に変換することを考えています。
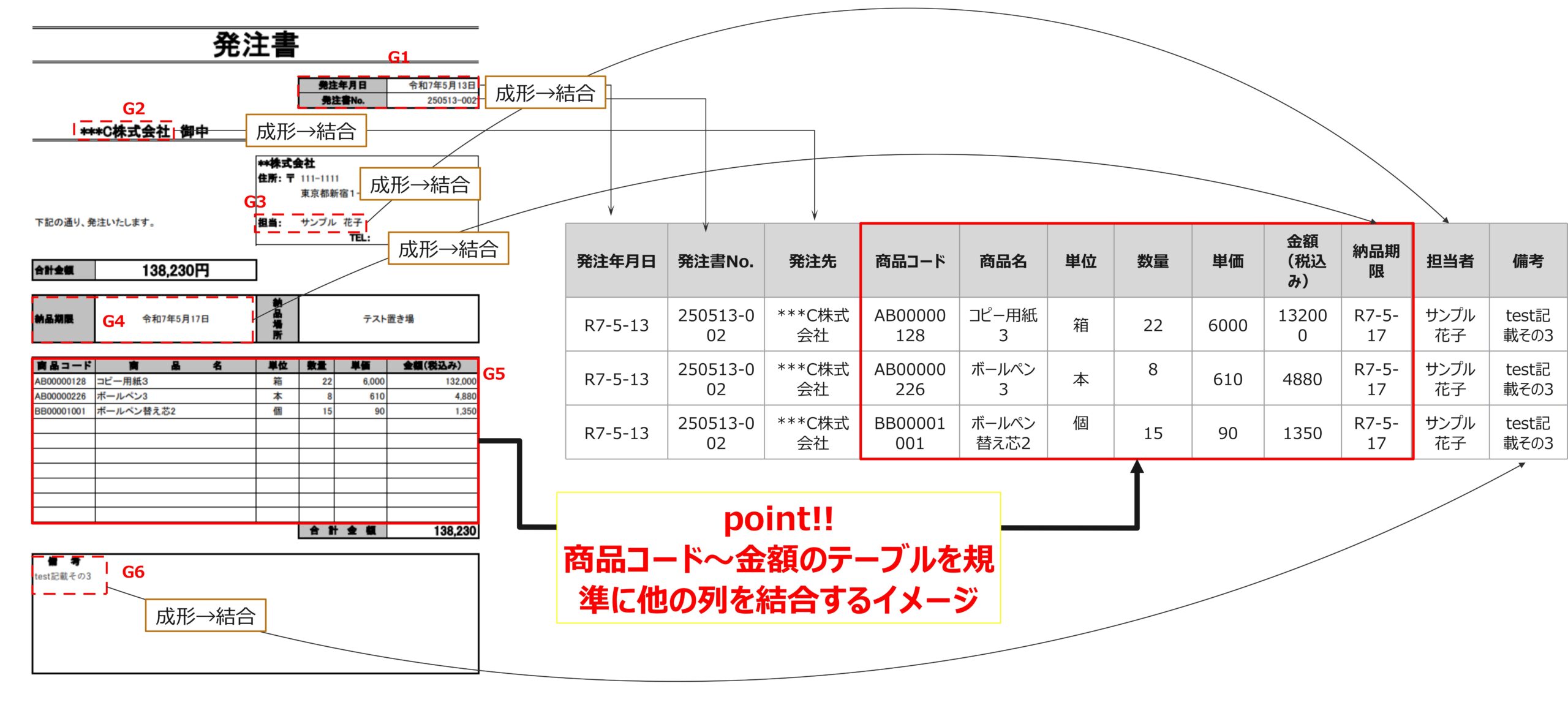
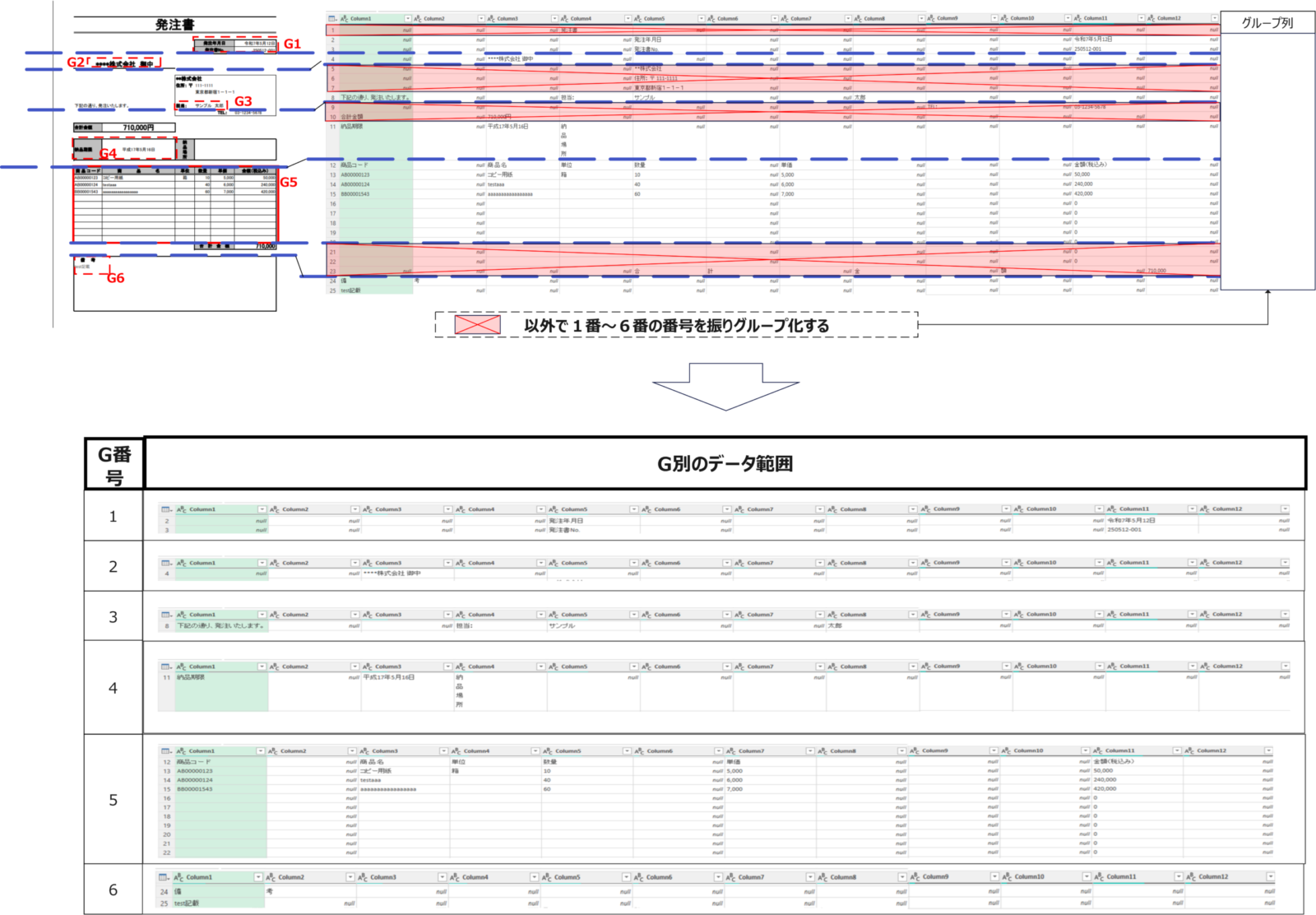
そのうえで、まずは取り込んだデータをグループ別にわけていく必要があります。今回のデータを改めてみてみると行方向にグループ化したい情報は分かれているため以下の手順で実装します。
- グループ番号を付与する列をカスタム列として追加
- 追加したカスタム列基準でテーブルをグループ化する
操作イメージ図としては以下になります。
↓実際操作まとめ↓
まずはインデックス列の追加します。これはグループ番号を追加する前準備であり、PDFの行番号と同一と思ってください。(この番号を基準にグループ番号を振る)
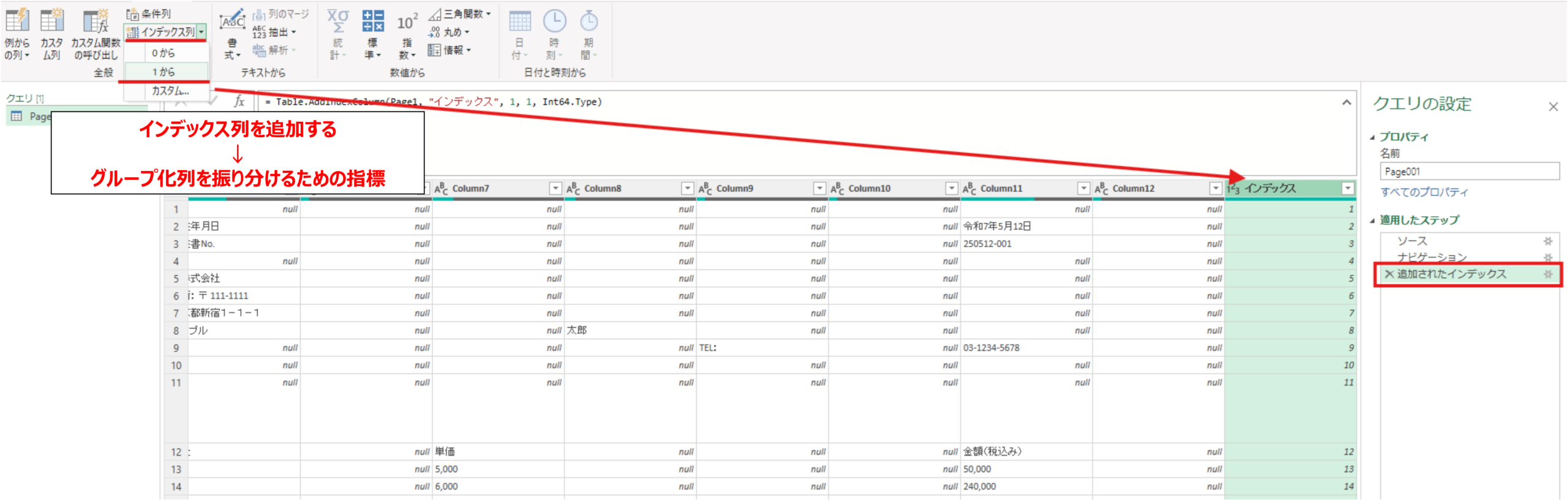
#インデックス追加のコード
追加されたインデックス = Table.AddIndexColumn(Page1, "インデックス", 1, 1, Int64.Type)次にカスタム列の追加して、各行に対して付与したいグループ番号を付与します。番号を振る式は以下の図もしくはコードスニペットを参考にしてください。インデックス列を基準にif文による条件分岐でグループ番号を付与しています。これはあくまで行方向が全てのPDFファイルで固定である前提です。
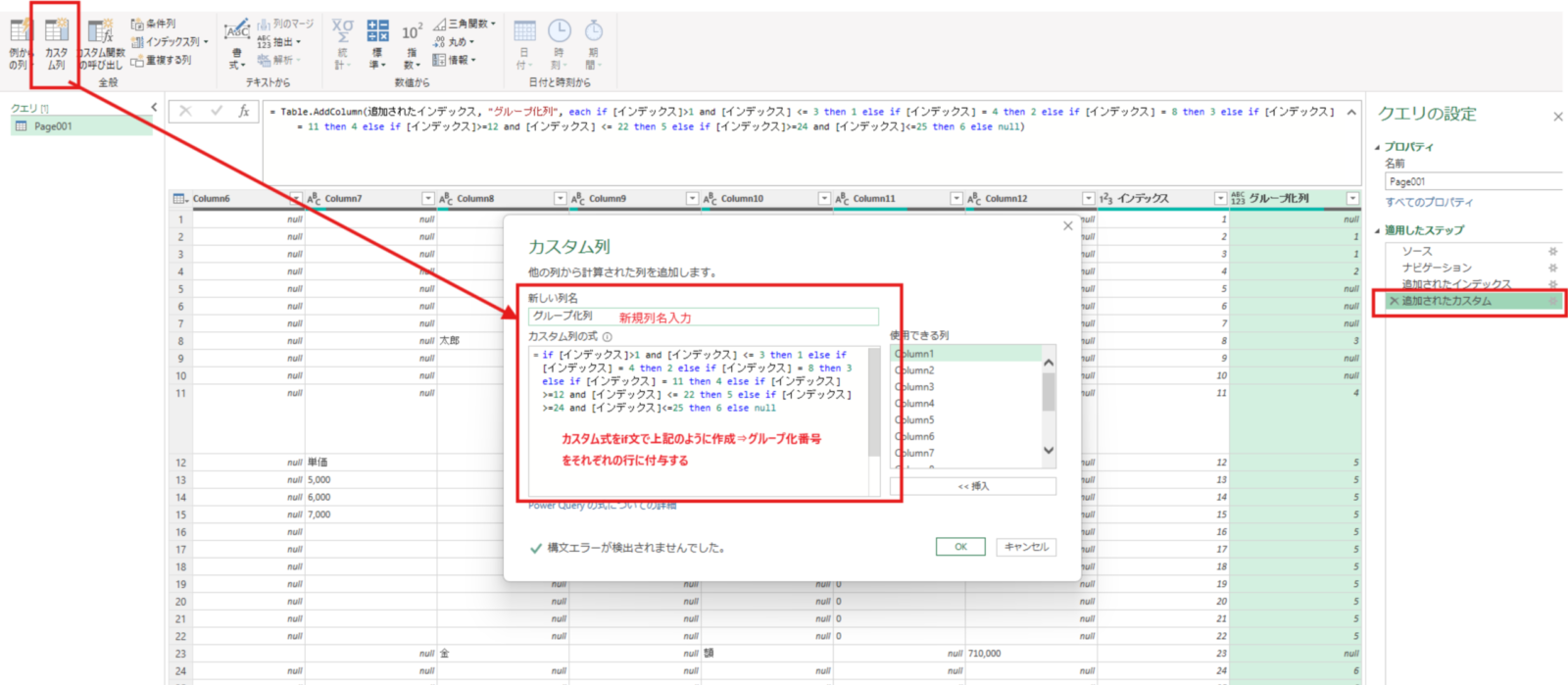
#グループ化列の追加
追加されたカスタム =
Table.AddColumn(
追加されたインデックス, "グループ化列", each
if [インデックス]>1 and [インデックス] <= 3 then 1
else if [インデックス] = 4 then 2
else if [インデックス] = 8 then 3
else if [インデックス] = 11 then 4
else if [インデックス]>=12 and [インデックス] <= 22 then 5
else if [インデックス]>=24 and [インデックス]<=25 then 6
else null
)次に、追加したグループ化列において “null”の行は不要のため削除しておきます。PowerQueryで特定の行を削除する最もオーソドックスなやり方はフィルター処理を実施するやり方です。以下のようにexcelのテーブルにフィルターをするようなやり方でnullの行を除去します。
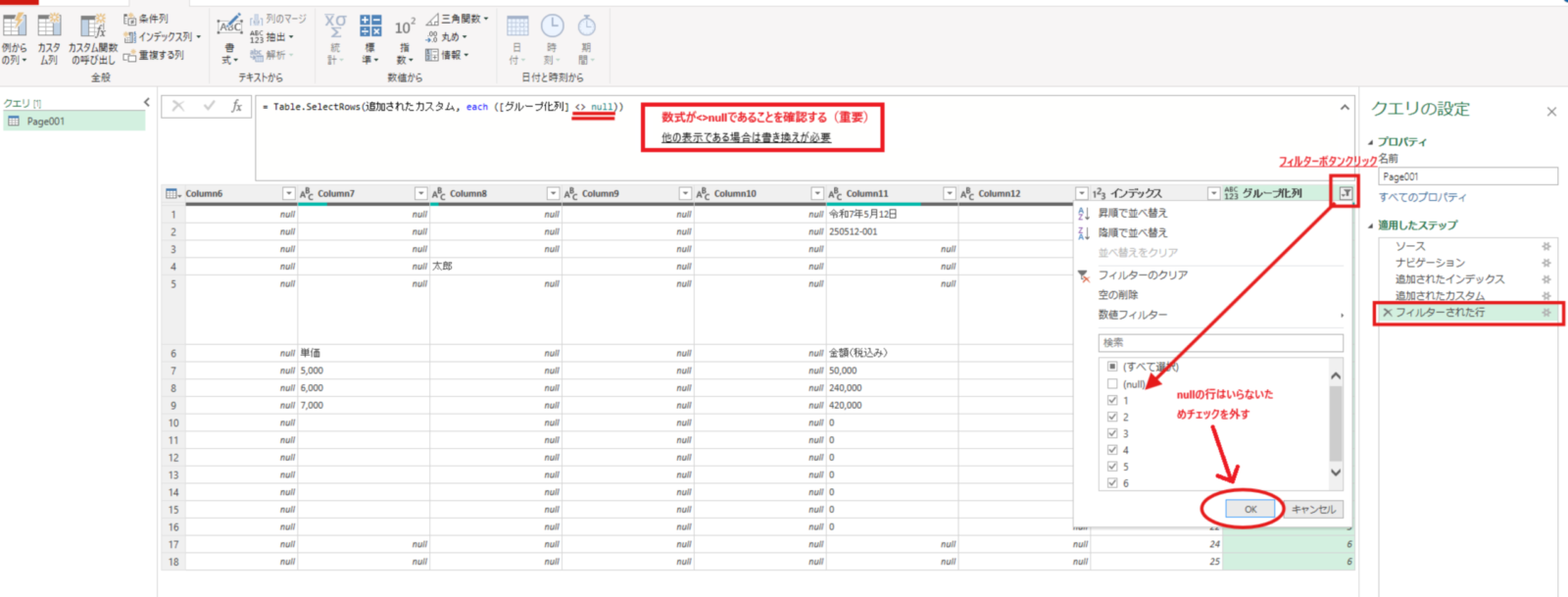
#フィルターの実施
フィルターされた行 = Table.SelectRows(追加されたカスタム, each ([グループ化列] <> null))注意点としてはこの操作ステップの数式バーの内容において、末尾付近が <>nullになっている必要があります。もし[グループ化列]=1 and [グループ化列]=2のような各グループ番号が条件式に組み込まれている場合は<>nullに書き換えておくことをお勧めします。
※今回の事例では全てのPDFで行番号が同じものを取り扱っているため問題はありませんが、行数が未知数でnull行だけ削除したい時に不具合が発生します。
グループ化番号を付与し終えたので、インデックス列は削除しておきます。
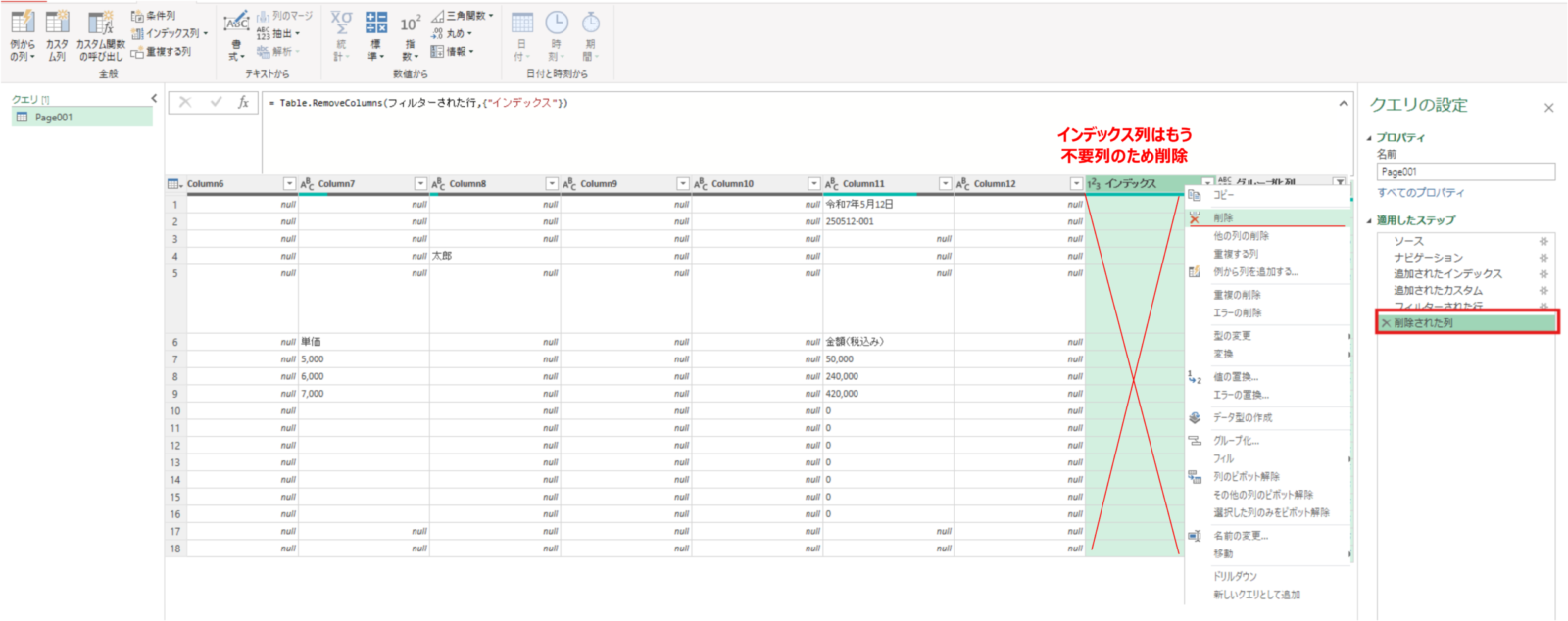
#インデックス列の削除
削除された列 = Table.RemoveColumns(フィルターされた行,{"インデックス"})最後にグループ化列を基準にグループ化の実施を行います。
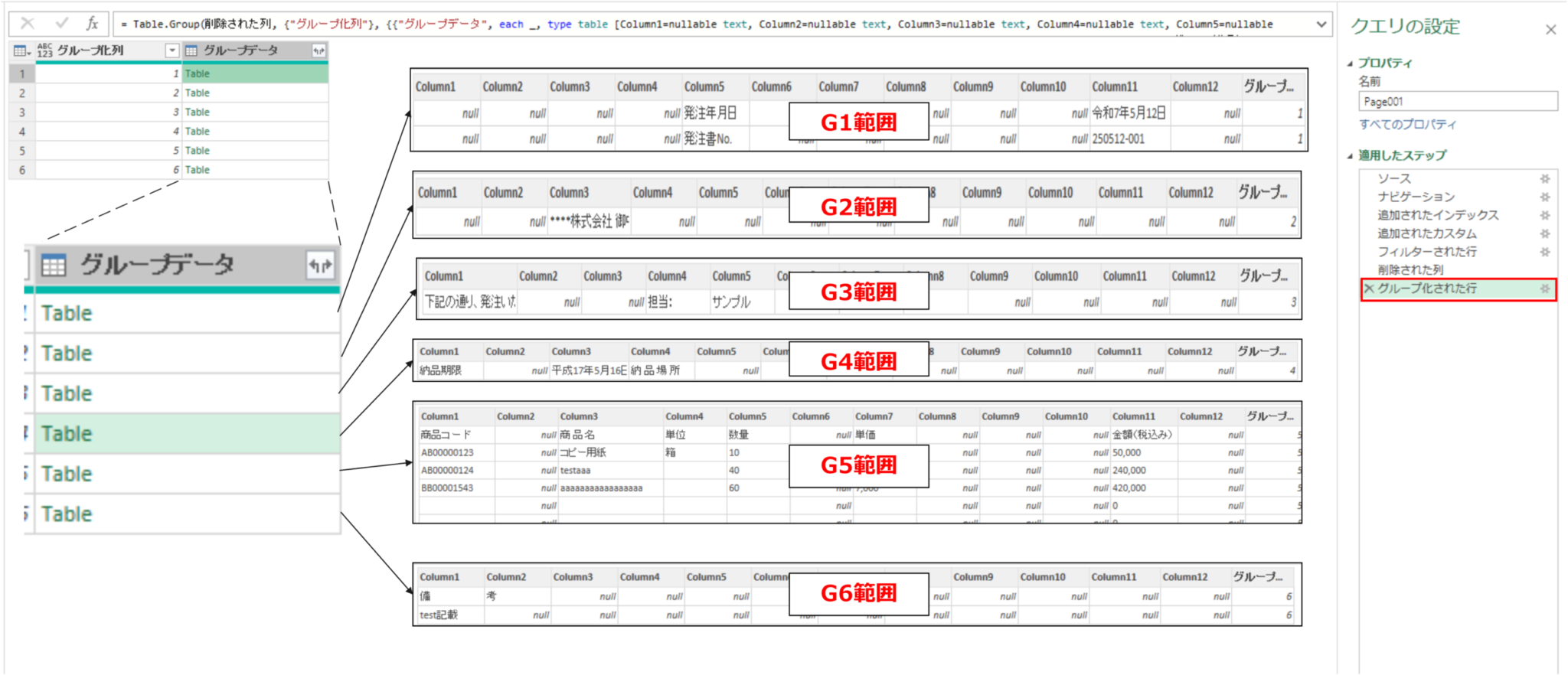
以下の画像に示すように、カスタム追加したグループ化列を選択した状態でグループ化を選択します。次にどのようなグループ集計計算をするか選択する画面になるので、全ての行を選択して適当な列名を入れてOKを押します。
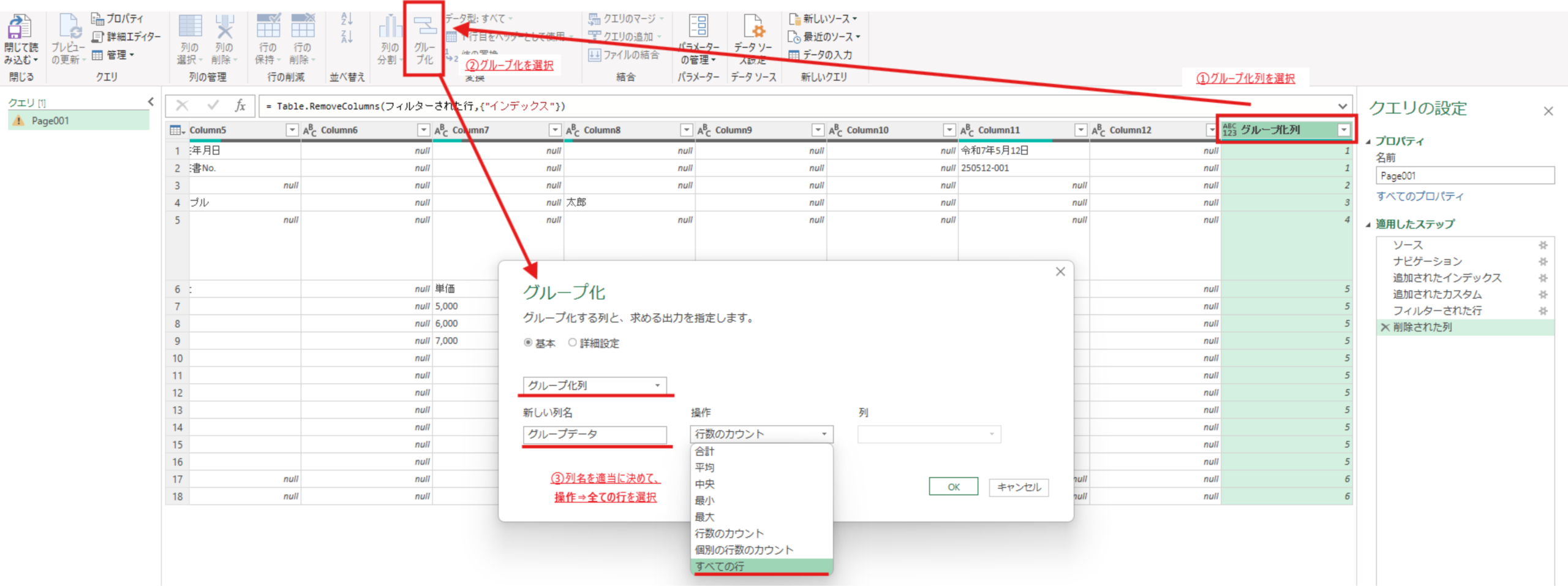
これによって以下のような、新規列に各グループ番号の行ごとが集まったテーブルデータが格納されます。⇒各テーブル毎に処理を分けて実施する前準備が整いました。(詳しくは次回の記事にて解説します)
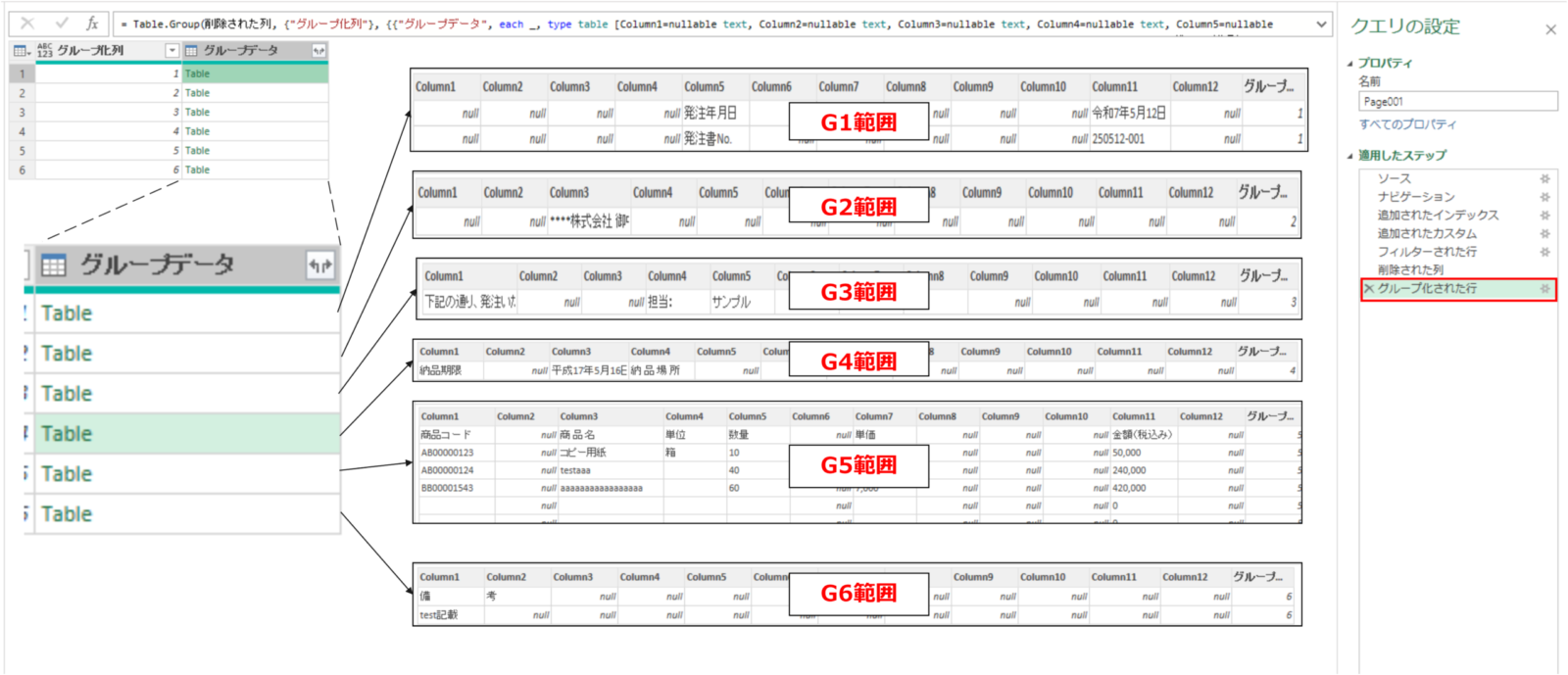
グループ化された行 =
Table.Group(
削除された列,
{"グループ化列"},
{{"グループデータ", each _,
type table [
Column1=nullable text, Column2=nullable text,Column3=nullable text,
Column4=nullable text, Column5=nullable text, Column6=nullable text,
Column7=nullable text,Column8=nullable text, Column9=nullable text,
Column10=nullable text,Column11=nullable text, Column12=nullable text,
グループ化列=number
]
}})なるほど。各行がどのグループに属するかの番号を振って、グループ化という操作をすればデータを分割できるんだね。これで実際の整理のステップに進めそうだよ!
このグループ化は整理するためには欠かせないまずやるべき操作だと思っています。
グループ化を実施することで、個別の整理が鮮明になって、後々の結合や処理の関数化もやりやすくなるので是非習得してみてください。
まとめ:PowerQueyでの注文書PDFファイルの最初のステップ・グループ化について説明
本記事では以下の内容に絞って説明しました。
- PowerQueryでPDFを取り込み、整理したい範囲毎にグループ化する方法について解説!!
次回は、グループ分けした各テーブルデータのそれぞれの整理ステップ・整理後の結合ステップについて解説していければと思います。このあたりから少し難しくなっていきますが頑張っていきましょう!!

以上、マー坊でした。

コメント